scala建表,hive查询为空
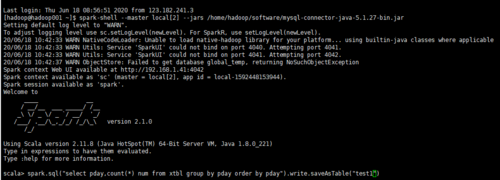
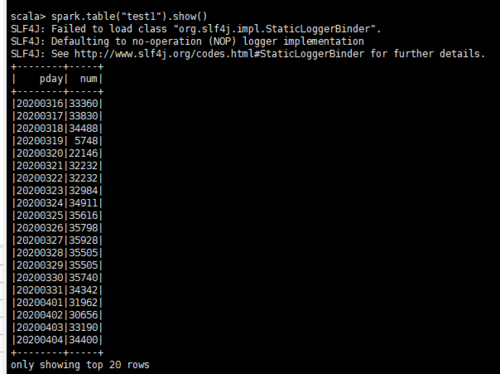
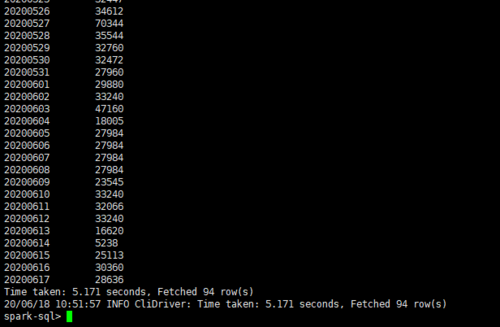
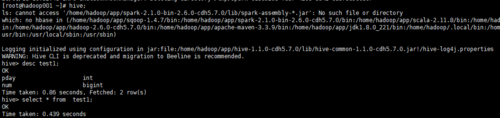
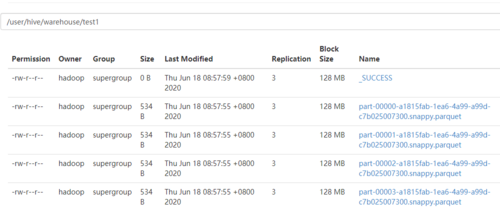
老师您好,我用scala命令spark.sql(“select pday,count(*) num from xtbl group by pday order by pday”).write.saveAsTable(“test1”)新建了一张test1表。之后用scala命令spark.table(“test1”).show()和sparksql都可以查到插入的数据内容。但是在hive里select查询出结果为空。
1497
收起
正在回答 回答被采纳积分+3
3回答


相似问题
Hive查数据库表,卡住不动
2258
1
5




pyspark可以访问hive但spark-submit访问不了hive
1925
0
3




hive 创建以后 mysql没有hive_hadoop的表
1921
1
19


diango orm 如何实现 前端为空即查询全部,有值按值查找?
1117
0
3



登录后可查看更多问答,登录/注册



