Selenium 返回乱码
老师请问我在爬取期货网站的时候发现是动态加载的,就打算用selenium来爬取。不论是用id还是css选择器还是xpath,爬取出来的结果都是这样的,您看: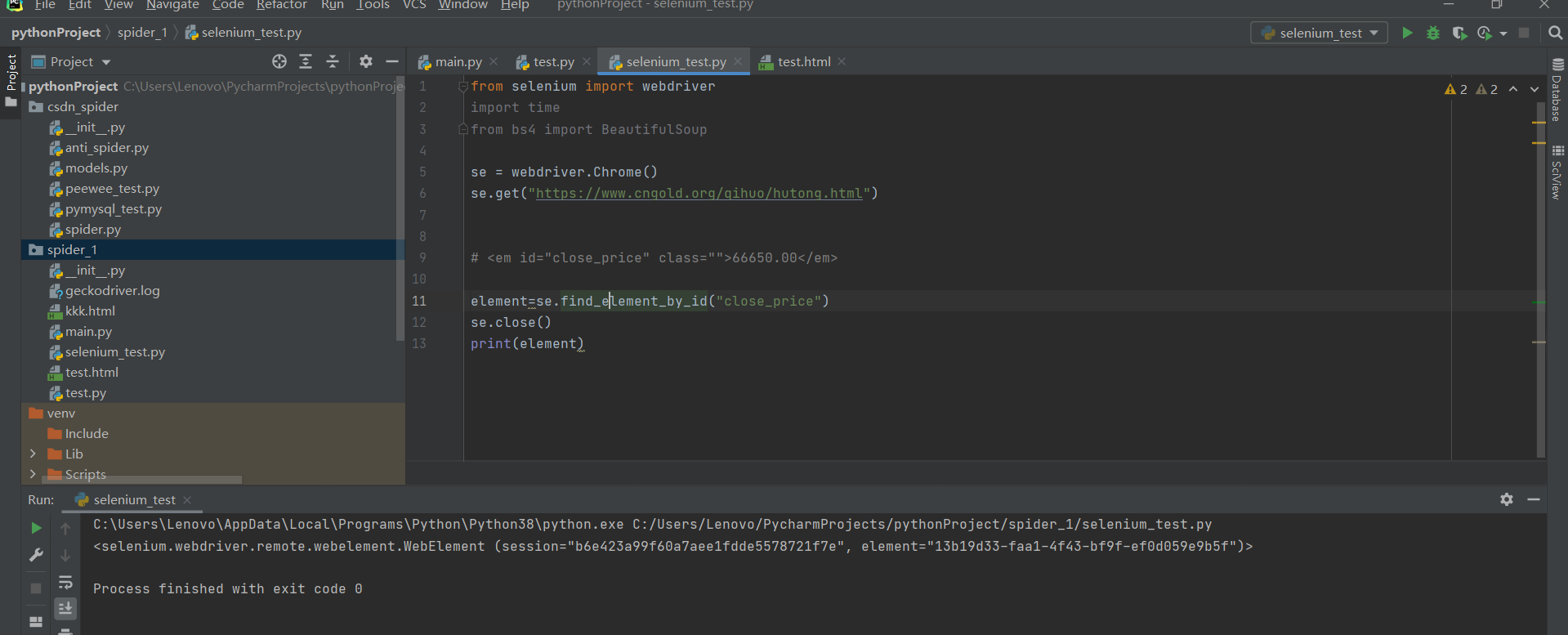
请问是遇到反爬了吗?
1607
收起
正在回答 回答被采纳积分+3
3回答

相似问题
请求CSD乱码
1800
0
6


使用curl命令时出现乱码怎么解决啊,到网上搜,感觉都没说清楚
2241
0
4


云函数中文传值乱码
1208
0
3


为什么要使用selenium
1846
1
6
html中文乱码
1360
0
8


登录后可查看更多问答,登录/注册




