提取网页元素
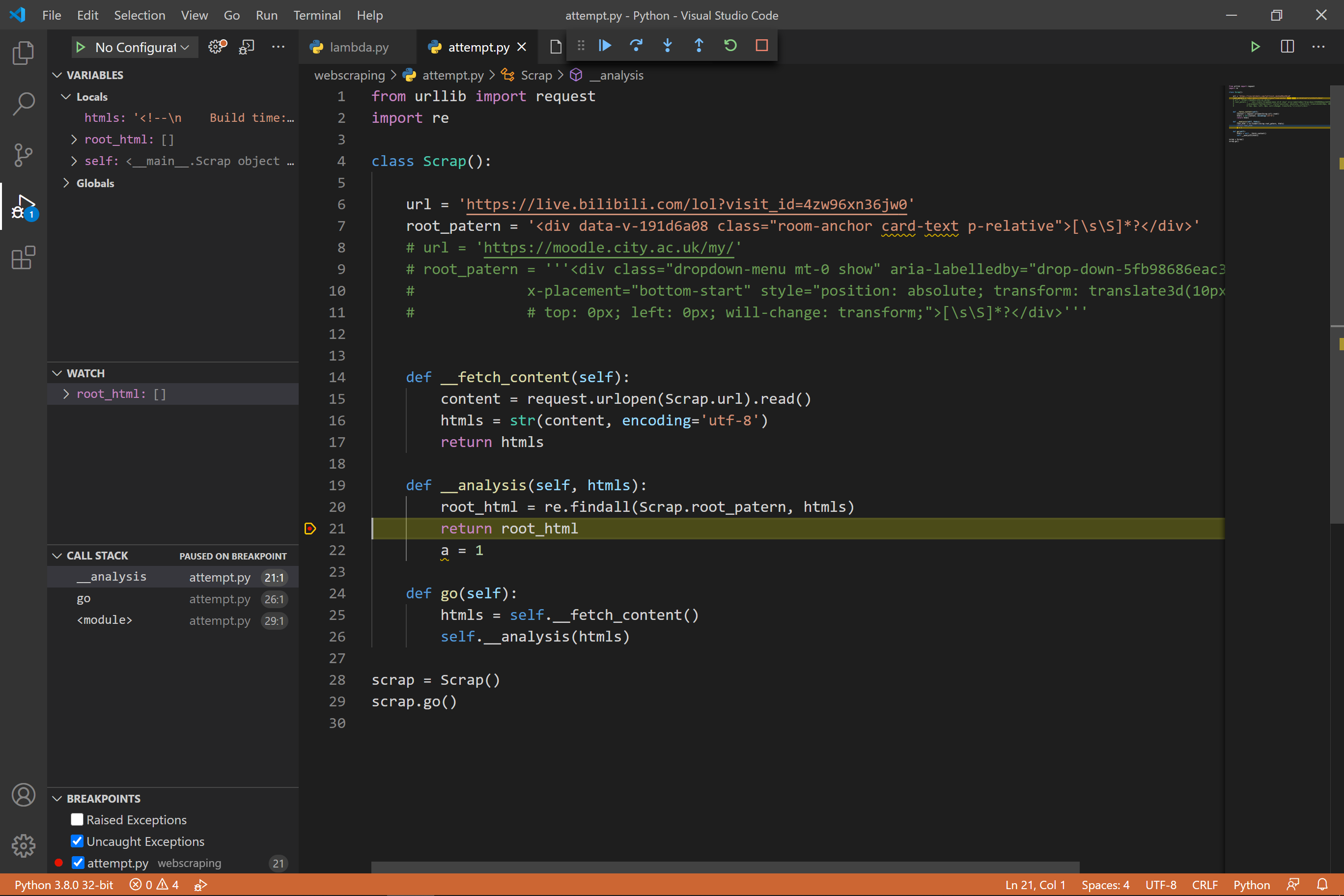 老师好,我想请问为什么我在提取网页元素的过程中发现返回的root_patern始终为空。__fetch_content()提取的htmls是成功的,但是后面的步骤就失败了。是我的正则表达式有问题吗?还是在代码调用上出了问题?
老师好,我想请问为什么我在提取网页元素的过程中发现返回的root_patern始终为空。__fetch_content()提取的htmls是成功的,但是后面的步骤就失败了。是我的正则表达式有问题吗?还是在代码调用上出了问题?
986
收起
正在回答 回答被采纳积分+3
1回答

相似问题
智联网页-无法有selenium定位
730
0
7




滚动查找到元素,提示元素is not clickable
989
0
3


selenium跳转到新页后,获取不到新页面的元素
1411
0
4
取得下一个元素
910
0
2


puppeteer抓取豆瓣网页信息的时候
1021
0
4






登录后可查看更多问答,登录/注册













