Flume和Kafka接收到数据后等待时间过长是什么原因呢?
以下是我的flume的conf文件配置
agent1.sources=avro-source agent1.channels=logger-channel agent1.sinks=kafka-sink #define source #agent1.sources.avro-source.type=avro agent1.sources.avro-source.type=netcat agent1.sources.avro-source.bind=0.0.0.0 agent1.sources.avro-source.port=41414 #define channel agent1.channels.logger-channel.type=memory #define sink agent1.sinks.kafka-sink.type=org.apache.flume.sink.kafka.KafkaSink agent1.sinks.kafka-sink.topic = access-topic-prod agent1.sinks.kafka-sink.brokerList = 192.168.189.142:9092 agent1.sinks.kafka-sink.requiredAcks = 1 agent1.sinks.kafka-sink.batchSize = 20 agent1.sources.avro-source.channels=logger-channel agent1.sinks.kafka-sink.channel=logger-channel
我在运行StreamingApp这个类的时候,通过网络TCP端口的方式向41414端口不断地传您logGenerator类产生的日志
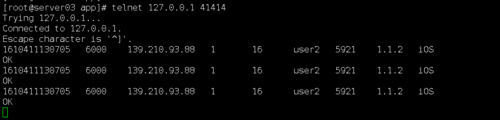
但是flume接收到日志以后貌似非常非常久以后才向Kafka发送数据(发送了一两次以后,第三次由于等待时间过长直接就不发送了!)
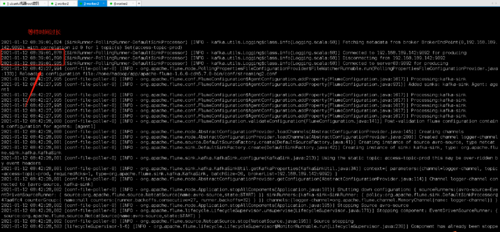
请问这是什么原因造成的呢?
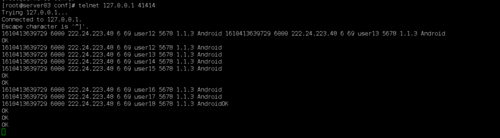
除此之外,批量处理不是一次性处理一大批数据吗?为什么我把一堆同样格式并且回过行的数据一起穿进来的时候为什么会报错(以下是我通过telnet传的批量数据)
1610413639729 6000 222.24.223.48 6 69 user12 5678 1.1.3 Android 1610413639729 6000 222.24.223.48 6 69 user13 5678 1.1.3 Android 1610413639729 6000 222.24.223.48 6 69 user14 5678 1.1.3 Android 1610413639729 6000 222.24.223.48 6 69 user15 5678 1.1.3 Android 1610413639729 6000 222.24.223.48 6 69 user16 5678 1.1.3 Android 1610413639729 6000 222.24.223.48 6 69 user17 5678 1.1.3 Android 1610413639729 6000 222.24.223.48 6 69 user18 5678 1.1.3 Android
streaming报错控制台:
Connected to the target VM, address: '127.0.0.1:50939', transport: 'socket' ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0) java.lang.NumberFormatException: For input string: "1610413639729 6000 222.24.223.48 6 69 user12 5678 1.1.3 Android" at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.lang.Long.parseLong(Long.java:589) at java.lang.Long.parseLong(Long.java:631) at scala.collection.immutable.StringLike.toLong(StringLike.scala:309) at scala.collection.immutable.StringLike.toLong$(StringLike.scala:309) at scala.collection.immutable.StringOps.toLong(StringOps.scala:33) at com.imooc.bigdata.project.utils.DateUtils$.parseToHour(DateUtils.scala:12) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$1(StreamingApp.scala:55) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:194) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:127) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:444) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:447) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) ERROR TaskSetManager: Task 0 in stage 0.0 failed 1 times; aborting job ERROR JobScheduler: Error running job streaming job 1610415110000 ms.0 org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0, MSI, executor driver): java.lang.NumberFormatException: For input string: "1610413639729 6000 222.24.223.48 6 69 user12 5678 1.1.3 Android" at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.lang.Long.parseLong(Long.java:589) at java.lang.Long.parseLong(Long.java:631) at scala.collection.immutable.StringLike.toLong(StringLike.scala:309) at scala.collection.immutable.StringLike.toLong$(StringLike.scala:309) at scala.collection.immutable.StringOps.toLong(StringOps.scala:33) at com.imooc.bigdata.project.utils.DateUtils$.parseToHour(DateUtils.scala:12) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$1(StreamingApp.scala:55) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:194) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:127) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:444) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:447) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2023) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:1972) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:1971) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1971) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:950) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:950) at scala.Option.foreach(Option.scala:407) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:950) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2203) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2152) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2141) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:752) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2093) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2114) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2133) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2158) at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$1(RDD.scala:994) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:388) at org.apache.spark.rdd.RDD.foreachPartition(RDD.scala:992) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$4(StreamingApp.scala:75) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$4$adapted(StreamingApp.scala:68) at org.apache.spark.streaming.dstream.DStream.$anonfun$foreachRDD$2(DStream.scala:629) at org.apache.spark.streaming.dstream.DStream.$anonfun$foreachRDD$2$adapted(DStream.scala:629) at org.apache.spark.streaming.dstream.ForEachDStream.$anonfun$generateJob$2(ForEachDStream.scala:51) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:417) at org.apache.spark.streaming.dstream.ForEachDStream.$anonfun$generateJob$1(ForEachDStream.scala:51) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.Try$.apply(Try.scala:213) at org.apache.spark.streaming.scheduler.Job.run(Job.scala:39) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.$anonfun$run$1(JobScheduler.scala:256) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.run(JobScheduler.scala:256) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Caused by: java.lang.NumberFormatException: For input string: "1610413639729 6000 222.24.223.48 6 69 user12 5678 1.1.3 Android" at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.lang.Long.parseLong(Long.java:589) at java.lang.Long.parseLong(Long.java:631) at scala.collection.immutable.StringLike.toLong(StringLike.scala:309) at scala.collection.immutable.StringLike.toLong$(StringLike.scala:309) at scala.collection.immutable.StringOps.toLong(StringOps.scala:33) at com.imooc.bigdata.project.utils.DateUtils$.parseToHour(DateUtils.scala:12) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$1(StreamingApp.scala:55) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:194) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:127) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:444) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:447) ... 3 more Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 1 times, most recent failure: Lost task 0.0 in stage 0.0 (TID 0, MSI, executor driver): java.lang.NumberFormatException: For input string: "1610413639729 6000 222.24.223.48 6 69 user12 5678 1.1.3 Android" at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.lang.Long.parseLong(Long.java:589) at java.lang.Long.parseLong(Long.java:631) at scala.collection.immutable.StringLike.toLong(StringLike.scala:309) at scala.collection.immutable.StringLike.toLong$(StringLike.scala:309) at scala.collection.immutable.StringOps.toLong(StringOps.scala:33) at com.imooc.bigdata.project.utils.DateUtils$.parseToHour(DateUtils.scala:12) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$1(StreamingApp.scala:55) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:194) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:127) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:444) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:447) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2023) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:1972) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:1971) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1971) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:950) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:950) at scala.Option.foreach(Option.scala:407) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:950) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2203) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2152) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2141) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:752) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2093) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2114) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2133) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2158) at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$1(RDD.scala:994) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:388) at org.apache.spark.rdd.RDD.foreachPartition(RDD.scala:992) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$4(StreamingApp.scala:75) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$4$adapted(StreamingApp.scala:68) at org.apache.spark.streaming.dstream.DStream.$anonfun$foreachRDD$2(DStream.scala:629) at org.apache.spark.streaming.dstream.DStream.$anonfun$foreachRDD$2$adapted(DStream.scala:629) at org.apache.spark.streaming.dstream.ForEachDStream.$anonfun$generateJob$2(ForEachDStream.scala:51) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:417) at org.apache.spark.streaming.dstream.ForEachDStream.$anonfun$generateJob$1(ForEachDStream.scala:51) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.Try$.apply(Try.scala:213) at org.apache.spark.streaming.scheduler.Job.run(Job.scala:39) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.$anonfun$run$1(JobScheduler.scala:256) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.run(JobScheduler.scala:256) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Caused by: java.lang.NumberFormatException: For input string: "1610413639729 6000 222.24.223.48 6 69 user12 5678 1.1.3 Android" at java.lang.NumberFormatException.forInputString(NumberFormatException.java:65) at java.lang.Long.parseLong(Long.java:589) at java.lang.Long.parseLong(Long.java:631) at scala.collection.immutable.StringLike.toLong(StringLike.scala:309) at scala.collection.immutable.StringLike.toLong$(StringLike.scala:309) at scala.collection.immutable.StringOps.toLong(StringOps.scala:33) at com.imooc.bigdata.project.utils.DateUtils$.parseToHour(DateUtils.scala:12) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$1(StreamingApp.scala:55) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at scala.collection.Iterator$$anon$10.next(Iterator.scala:459) at org.apache.spark.util.collection.ExternalSorter.insertAll(ExternalSorter.scala:194) at org.apache.spark.shuffle.sort.SortShuffleWriter.write(SortShuffleWriter.scala:62) at org.apache.spark.shuffle.ShuffleWriteProcessor.write(ShuffleWriteProcessor.scala:59) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:99) at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:52) at org.apache.spark.scheduler.Task.run(Task.scala:127) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:444) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:447) ... 3 more ERROR Inbox: Ignoring error java.util.concurrent.RejectedExecutionException: Task org.apache.spark.executor.Executor$TaskRunner@63160b6d rejected from java.util.concurrent.ThreadPoolExecutor@63a9d3ab[Terminated, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 1] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2047) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:823) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1369) at org.apache.spark.executor.Executor.launchTask(Executor.scala:228) at org.apache.spark.scheduler.local.LocalEndpoint.$anonfun$reviveOffers$1(LocalSchedulerBackend.scala:93) at org.apache.spark.scheduler.local.LocalEndpoint.$anonfun$reviveOffers$1$adapted(LocalSchedulerBackend.scala:91) at scala.collection.Iterator.foreach(Iterator.scala:941) at scala.collection.Iterator.foreach$(Iterator.scala:941) at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at scala.collection.AbstractIterable.foreach(Iterable.scala:56) at org.apache.spark.scheduler.local.LocalEndpoint.reviveOffers(LocalSchedulerBackend.scala:91) at org.apache.spark.scheduler.local.LocalEndpoint$$anonfun$receive$1.applyOrElse(LocalSchedulerBackend.scala:68) at org.apache.spark.rpc.netty.Inbox.$anonfun$process$1(Inbox.scala:115) at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:203) at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:100) at org.apache.spark.rpc.netty.MessageLoop.org$apache$spark$rpc$netty$MessageLoop$$receiveLoop(MessageLoop.scala:75) at org.apache.spark.rpc.netty.MessageLoop$$anon$1.run(MessageLoop.scala:41) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Exception in thread "streaming-job-executor-0" java.lang.Error: java.lang.InterruptedException at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1148) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Caused by: java.lang.InterruptedException at java.util.concurrent.locks.AbstractQueuedSynchronizer.doAcquireSharedInterruptibly(AbstractQueuedSynchronizer.java:998) at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireSharedInterruptibly(AbstractQueuedSynchronizer.java:1304) at scala.concurrent.impl.Promise$DefaultPromise.tryAwait(Promise.scala:242) at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:258) at scala.concurrent.impl.Promise$DefaultPromise.ready(Promise.scala:187) at org.apache.spark.util.ThreadUtils$.awaitReady(ThreadUtils.scala:335) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:743) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2093) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2114) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2133) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2158) at org.apache.spark.rdd.RDD.$anonfun$foreachPartition$1(RDD.scala:994) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:388) at org.apache.spark.rdd.RDD.foreachPartition(RDD.scala:992) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$9(StreamingApp.scala:101) at com.imooc.bigdata.project.stream.StreamingApp$.$anonfun$main$9$adapted(StreamingApp.scala:100) at org.apache.spark.streaming.dstream.DStream.$anonfun$foreachRDD$2(DStream.scala:629) at org.apache.spark.streaming.dstream.DStream.$anonfun$foreachRDD$2$adapted(DStream.scala:629) at org.apache.spark.streaming.dstream.ForEachDStream.$anonfun$generateJob$2(ForEachDStream.scala:51) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at org.apache.spark.streaming.dstream.DStream.createRDDWithLocalProperties(DStream.scala:417) at org.apache.spark.streaming.dstream.ForEachDStream.$anonfun$generateJob$1(ForEachDStream.scala:51) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.Try$.apply(Try.scala:213) at org.apache.spark.streaming.scheduler.Job.run(Job.scala:39) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.$anonfun$run$1(JobScheduler.scala:256) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62) at org.apache.spark.streaming.scheduler.JobScheduler$JobHandler.run(JobScheduler.scala:256) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) ... 2 more Disconnected from the target VM, address: '127.0.0.1:50939', transport: 'socket' Process finished with exit code 1
1097
收起
正在回答 回答被采纳积分+3
1回答
相似问题
线程平均等待时间和平均工作时间问题
1363
0
3


老师,你好,通过学习课程进行实际生产的使用,但是出现以下问题
910
0
4


关于启动 等待计时器 的问题
1295
0
2


UDPProvider和UDPSearcher的启动顺序
1511
1
7






登录后可查看更多问答,登录/注册








