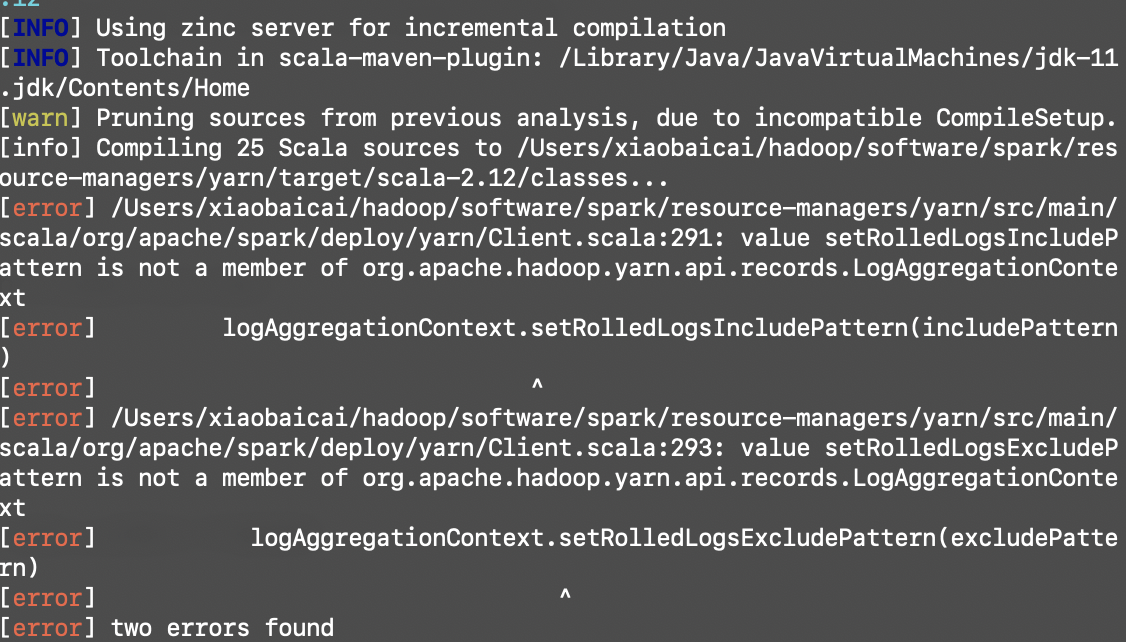
正在回答
2回答

相似问题
spark如何基于cdh版本hadoop进行编译啊?
1259
0
3


Spark编译成功后该怎么办
1176
0
5
spark源码编译错误
1448
0
7
还是Spark编译问题
1353
0
2


spark在本机上的编译问题
1309
0
4
登录后可查看更多问答,登录/注册




