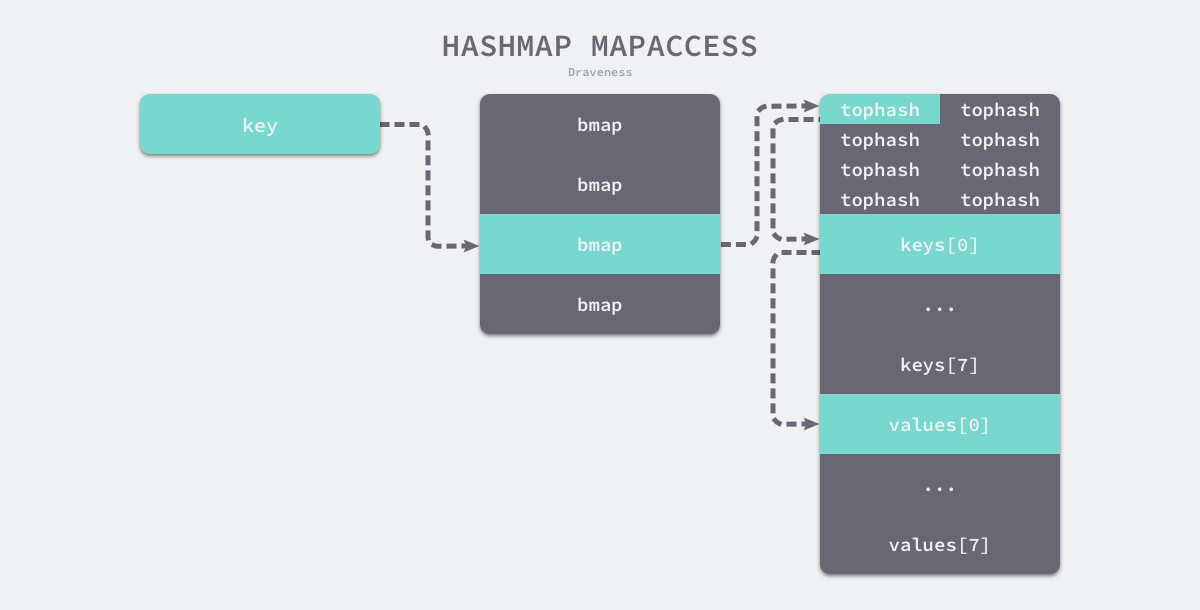
对于map的元素查找,源码实现如下:
func mapaccess1(t *maptype, h *hmap, key unsafe.Pointer) unsafe.Pointer {
// 如果开启了竞态检测 -race if raceenabled && h != nil {
callerpc := getcallerpc()
pc := funcPC(mapaccess1)
racereadpc(unsafe.Pointer(h), callerpc, pc)
raceReadObjectPC(t.key, key, callerpc, pc)
}
// 如果开启了memory sanitizer -msan if msanenabled && h != nil {
msanread(key, t.key.size)
}
// 如果map为空或者元素个数为0,返回零值 if h == nil || h.count == 0 {
if t.hashMightPanic() {
t.hasher(key, 0) // see issue 23734 }
return unsafe.Pointer(&zeroVal[0])
}
// 注意,这里是按位与操作 // 当h.flags对应的值为hashWriting(代表有其他goroutine正在往map中写key)时,那么位计算的结果不为0,因此抛出以下错误。 // 这也表明,go的map是非并发安全的 if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 不同类型的key,会使用不同的hash算法,可详见src/runtime/alg.go中typehash函数中的逻辑 hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
// 按位与操作,找到对应的bucket b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
// 如果oldbuckets不为空,那么证明map发生了扩容 // 如果有扩容发生,老的buckets中的数据可能还未搬迁至新的buckets里 // 所以需要先在老的buckets中找 if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
// 如果在oldbuckets中tophash[0]的值,为evacuatedX、evacuatedY,evacuatedEmpty其中之一 // 则evacuated()返回为true,代表搬迁完成。 // 因此,只有当搬迁未完成时,才会从此oldbucket中遍历 if !evacuated(oldb) {
b = oldb
}
}
// 取出当前key值的tophash值 top := tophash(hash)
// 以下是查找的核心逻辑 // 双重循环遍历:外层循环是从桶到溢出桶遍历;内层是桶中的cell遍历 // 跳出循环的条件有三种:第一种是已经找到key值;第二种是当前桶再无溢出桶; // 第三种是当前桶中有cell位的tophash值是emptyRest,这个值在前面解释过,它代表此时的桶后面的cell还未利用,所以无需再继续遍历。bucketloop:
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
// 判断tophash值是否相等 if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
// 因为在bucket中key是用连续的存储空间存储的,因此可以通过bucket地址+数据偏移量(bmap结构体的大小)+ keysize的大小,得到k的地址 // 同理,value的地址也是相似的计算方法,只是再要加上8个keysize的内存地址 k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
// 判断key是否相等 if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
// 所有的bucket都未找到,则返回零值 return unsafe.Pointer(&zeroVal[0])}如果理解了map的结构,就不难理解这个问题,先看map的存储结构:
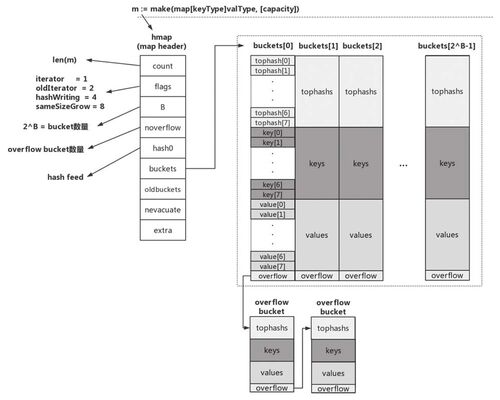
首先每个桶中最多只有8个元素,也就是只能存储8个键值对。当某个bucket(比如buckets[0])的8个空槽(slot)都已填满且map尚未达到扩容条件时,运行时会建立overflow bucket,并将该overflow bucket挂在上面bucket(如buckets[0])末尾的overflow指针上,这样两个bucket形成了一个链表结构,该结构的存在将持续到下一次map扩容。
这样对于上面的bucket[0]中,实际上是有很多个这种8个元素为一组的这种bucket的,我们可以将这样一组bucket理解成一个cell。那么通过高8位去定位key在bucket[0]里边的位置的时候,就得对整个bucket[0]的cell进行遍历,然后也需要对cell中的元素进行遍历。tophash是用于快速定位key位置的,它存储的是高8位的tophash值。