老师,jd_spider中数据插入Mysql时一直显示主键错误,求助~
老师,jd_spider中数据插入Mysql时一直显示主键错误,求助~
而且peewee会自动生成一个goods表的主键
万分感谢!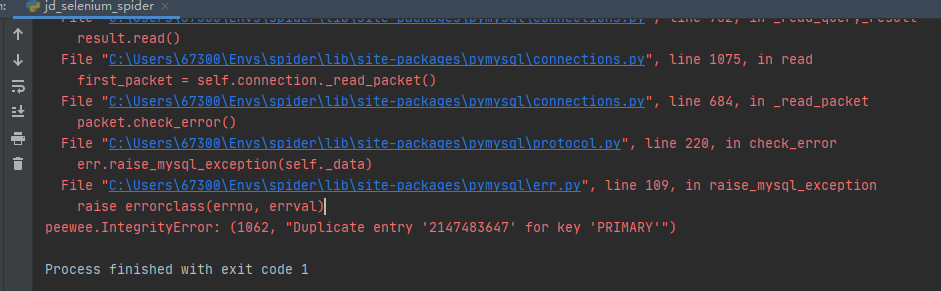
建立表的代码如下
from peewee import *
db = MySQLDatabase('spider', host='localhost', port=3306, user='root', password='a83421967')
class BaseModel(Model):
class Meta:
database = db
class Goods(BaseModel):
id = IntegerField(primary_key=True, verbose_name="商品id")
name = CharField(max_length=500, verbose_name="商品名称")
description = TextField(default="", verbose_name="商品描述")
price = FloatField(default=0.0, verbose_name="商品价格")
supplier = CharField(default="", verbose_name="商品销售商")
product_content = TextField(default="", verbose_name="规格包装")
comments_nums = CharField(default='0', verbose_name="商品评论数")
images_list = TextField(default="", verbose_name="轮播图片地址")
good_rate = FloatField(default=0.0, verbose_name="好评率")
image_comments_nums = CharField(default='0', verbose_name="评论晒图数")
video_comments_nums = CharField(default='0', verbose_name="评论视频数")
add_comment_nums = CharField(default='0', verbose_name="追评数")
well_comment_nums = CharField(default='0', verbose_name="好评率")
medium_comment_nums = CharField(default='0', verbose_name="中评率")
bad_comment_nums = CharField(default='0', verbose_name="差评数")
class GoodsEvaluate(BaseModel):
id = CharField(primary_key=True)
goods_id = ForeignKeyField(Goods, verbose_name="商品id")
user_head_url = CharField(verbose_name="用户头像")
user_name = CharField(verbose_name="用户名")
good_info = CharField(max_length=500, verbose_name="购买的商品的信息")
evaluate_time = DateTimeField(verbose_name="评价时间")
content = TextField(default="", verbose_name="评论内容")
star = IntegerField(default=0, verbose_name="评分")
comment_nums = IntegerField(default=0, verbose_name="评论数")
praised_nums = IntegerField(default=0, verbose_name="点赞数")
image_list = TextField(default="", verbose_name="图片")
video_list = TextField(default="", verbose_name="视频")
class GoodsEvaluateSummary(BaseModel):
id = AutoField()
goods_id = ForeignKeyField(Goods, verbose_name="商品id")
tag = CharField(max_length=20, verbose_name="评论标签")
tag_nums = IntegerField(default=0, verbose_name="该标签评论数")
if __name__ == "__main__":
db.create_tables([Goods, GoodsEvaluate, GoodsEvaluateSummary])
jd_spider代码如下
import json
import time
import re
from datetime import datetime
from selenium import webdriver
from scrapy import Selector
from selenium.common.exceptions import NoSuchElementException
from jd_spider.model_charts import *
browser = webdriver.Chrome(executable_path=r"E:\王雨\python\chromedriver_win32\chromedriver.exe")
def process_value(nums_str):
"""
将字符型的数字转换成数字
:param nums_str:字符型数字
:return:成功返回数字,默认返回零
"""
nums = 0
re_search = re.search(r"\d+", nums_str)
if re_search:
nums = re_search.group(0)
if "万" in nums_str:
nums *= 10000
return nums
def get_goods(goods_id):
url = "https://item.jd.com/{}.html".format(goods_id)
browser.get(url)
# 提取商品基本信息
sel = Selector(text=browser.page_source)
goods = Goods(id=goods_id)
name = "".join(sel.xpath("//div[@class='sku-name']/text()").extract()).strip()
goods.name = name
price = sel.xpath("//span[@class='price J-p-{}']/text()".format(goods_id)).extract_first()
price = float(price)
goods.price = price
detail = "".join(sel.xpath("//div[@id='detail']//div[@class='tab-con']").extract())
goods.description = detail
img_list = sel.xpath("//div[@id='spec-list']//img/@src").extract()
goods.images_list = json.dumps(img_list)
supplier = "".join(sel.xpath("//div[@id='summary-service']").extract())
supplier_info = re.search(r'<a href="//(.+).jd.com"', supplier)
if supplier_info:
goods.supplier = supplier_info.group(1)
else:
goods.supplier = "京东"
# 模拟点击规格包装获取信息
ggbj_ele = browser.find_element_by_xpath("//li[contains(text(),'规格与包装')]")
ggbj_ele.click()
time.sleep(3)
sel = Selector(text=browser.page_source)
ggbj = "".join(sel.xpath("//div[@id='detail']/div[@class='tab-con']").extract())
goods.product_content = ggbj
# 模拟点击商品评价获取评价信息
sppj_ele = browser.find_element_by_xpath("//li[@data-anchor='#comment']")
sppj_ele.click()
time.sleep(3)
dqpj_ele = browser.find_element_by_xpath("//input[@id='comm-curr-sku']")
dqpj_ele.send_keys("\n")
time.sleep(3)
sel = Selector(text=browser.page_source)
good_rate = "".join(sel.xpath("//div[@class='percent-con']/text()").extract()).strip()
goods.good_rate = float(good_rate)/100
tag_list = sel.xpath("//div[@class='tag-list tag-available']//span/text()").extract()
summary_list = sel.xpath("//ul[@class='filter-list']//li/a")
for a in summary_list:
name = a.xpath("./text()").extract()[0]
nums = a.xpath("./em/text()").extract()[0]
nums = process_value(nums)
if name == "全部评价":
goods.comments_nums = nums
if name == "晒图":
goods.image_comments_nums = nums
if name == "视频晒单":
goods.video_comments_nums = nums
if name == "追评":
goods.add_comment_nums = nums
if name == "好评":
goods.well_comment_nums = nums
if name == "中评":
goods.medium_comment_nums = nums
if name == "差评":
goods.bad_comment_nums = nums
# 保存商品信息
existed_goods = Goods().select().where(Goods.id == goods.id)
if existed_goods:
goods.save()
else:
goods.save(force_insert=True)
for tag in tag_list:
re_match = re.match(r"(.+)\((\d+)\)", tag)
if re_match:
name = re_match.group(1)
nums = int(re_match.group(2))
existed_tag = GoodsEvaluateSummary.select().where(GoodsEvaluateSummary.goods_id==goods, GoodsEvaluateSummary.tag==name)
if existed_tag:
summary = existed_tag[0]
else:
summary = GoodsEvaluateSummary(goods_id=goods.id)
summary.tag = name
summary.tag_nums = nums
summary.save()
# 获取商品评价详情
have_next_page = True
while have_next_page:
all_div = sel.xpath("//div[@class='comment-item']")
for div in all_div:
good_evaluate = GoodsEvaluate(goods_id=goods.id)
user_name = "".join(div.xpath(".//div[@class='user-info']/text()").extract()).strip()
good_evaluate.user_name = user_name
user_img_url = div.xpath(".//div[@class='user-info']/img/@src").extract_first()
good_evaluate.user_head_url = user_img_url
comment_info = "".join(div.xpath(".//p[@class='comment-con']/text()").extract()).strip()
good_evaluate.content = comment_info
star_nums = div.xpath(".//div[contains(@class,'comment-star')]/@class").extract_first()
good_evaluate.star = int(star_nums[-1])
praise_nums = "".join(div.xpath(".//i[@class='sprite-praise']/../text()").extract()).strip()
good_evaluate.praised_nums = int(praise_nums)
comment_nums = "".join(div.xpath(".//i[@class='sprite-comment']/../text()").extract()).strip()
good_evaluate.comment_nums = comment_nums
order_info = div.xpath(".//div[@class='order-info']/span/text()").extract()
order_detail = order_info[:-1]
good_evaluate.good_info = json.dumps(order_detail)
good_evaluate.evaluate_time = datetime.strptime(order_info[-1], "%Y-%m-%d %H:%M")
comment_img = div.xpath(".//div[@class='pic-list J-pic-list']/a/img/@src").extract()
good_evaluate.image_list = json.dumps(comment_img)
comment_video = div.xpath(".//div[@class='J-video-view-wrap clearfix']//video/@src").extract()
good_evaluate.video_list = json.dumps(comment_video)
evaluate_id = div.xpath("./@data-guid").extract()[0]
good_evaluate.id = evaluate_id
existed_evaluate = GoodsEvaluate.select().where(GoodsEvaluate.id == good_evaluate.id)
if existed_evaluate:
good_evaluate.save()
else:
good_evaluate.save(force_insert=True)
try:
next_page_ele = browser.find_element_by_xpath("//div[@class='com-table-footer']//a[@class='ui-pager-next']")
next_page_ele.send_keys("\n")
sel = Selector(text=browser.page_source)
except NoSuchElementException as e:
have_next_page = False
if __name__ == "__main__":
get_goods(56166176873)
1154
收起
正在回答 回答被采纳积分+3
1回答

相似问题







登录后可查看更多问答,登录/注册





