HashMap中扩容时的问题
老师好,这几天看HashMap的源码,1.7 1.8都看了,在扩容的时候有点疑问
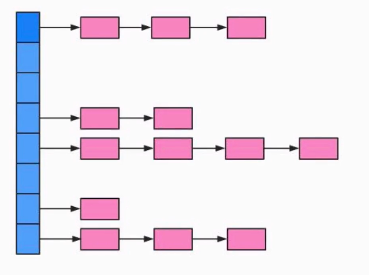
比如说像上面那个图,有4个Key,都放在了一个桶里,扩容的时候,这4个key不应该还是在一个桶里吗,因为这4个key之前放在一个桶里说明他们hashCode是相同的,在1.7里有一个indexFor()的方法,求出应该存放在哪个桶里的下标,传入的是hash值和新的容量。。他们hash后都是相同的呀,求出的新下标不应该也是相同的吗,这里有点不理解。。。
1812
收起
正在回答 回答被采纳积分+3
1回答

相似问题





登录后可查看更多问答,登录/注册


