关于ThreadPoolExecutor
我设置的最大线程数为10.
如果不用as_completed方法,则运行结果如下,只运行了10个线程就退出程序了: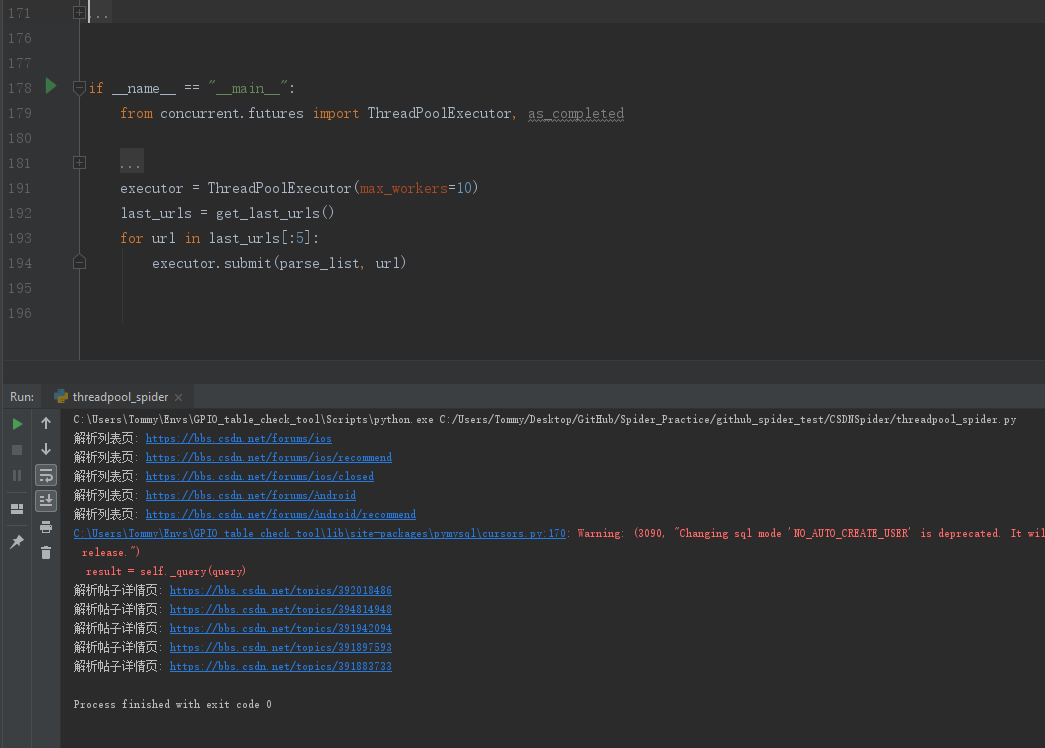
如果使用as_completed方法,则会跑完所有的线程,结果如下: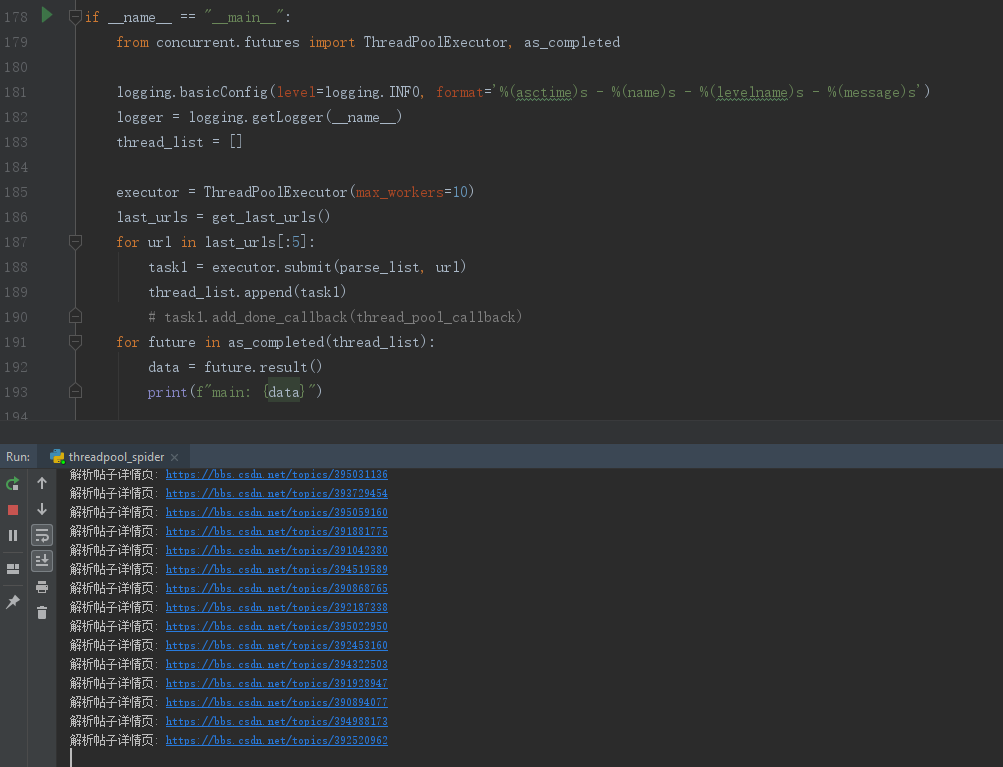
老师的代码中并没有加as_completed方法,以上代码是我从老师的git仓库下载的。我也不懂到底需不需要加as_completed方法。对ThreadPoolExecutor还是不是很理解,希望老师可以解答下。
1094
收起
正在回答 回答被采纳积分+3
4回答


相似问题
关于common.SessionName的问题
886
0
2


关于ThreadPoolExecutor的不理解
518
0
2


关于线程池的创建问题
1141
0
1


ThreadPoolExecutor的workQueue参数
1066
1
2


关于课程优化上的一点建议
1305
1
3


登录后可查看更多问答,登录/注册





