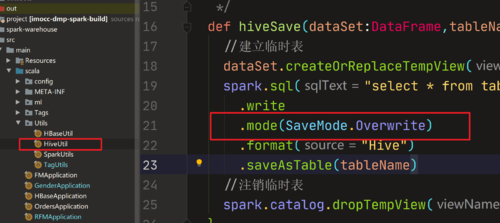
老师可以讲一下存储hive数仓的详细步骤吗?
按照代码里面的逻辑,每次存进dw.dws_user_action_tags_map_all执行的是全量覆盖,怎么样实现标签流水表和标签主题表的增量存储呢?如果是多个job协同的话,应该怎样调度呢?
606
收起
正在回答 回答被采纳积分+3
1回答

相似问题
为什么推荐用异步的存储而不是同步的存储?
985
0
2



通过Hive创建数据库成功,但没有在Mysql找到对应的test_db
2643
0
5


发现一个神奇的问题请教一下老师
1045
0
8
Hive查数据库表,卡住不动
2239
1
5


登录后可查看更多问答,登录/注册




