csdn 网页代码发生变化
csdn 网页代码发生变化
td class=“forums_topic”>
<span class="green">[置顶]</span>
<a href="/forums/placard" target="_blank" class="forums_t">社区公告・</a>
<a href="/topics/392570959" class="forums_title title_style_red title_style_bold" target="_blank" title="送!机械键盘、盖泡面Kindle、西二旗防堵山地车、真无线AirPods、找Bug雨伞,CSDN百万粉丝狂欢!">送!机械键盘、盖泡面Kindle、西二旗防堵山地车、真无线AirPods、找Bug雨伞,CSDN百万粉丝狂欢!</a>
<span class="red">[推荐]</span>
每个 td 下面 都出现 2个 a标签
这样取 topic_url = parse.urljoin(domain, tr.xpath(".//td[3]/a/@href").extract()[0])
只能取到第一个 href="/forums/placard" 的值
所以改成topic_url = parse.urljoin(domain, tr.xpath(".//td[3]/a[2]/@href").extract()[0])
能取到前两个列表的 href="/topics/392570959" 值
这样才能取出ID:392570959
运行可以取到 前两个列表的值,后边就会报错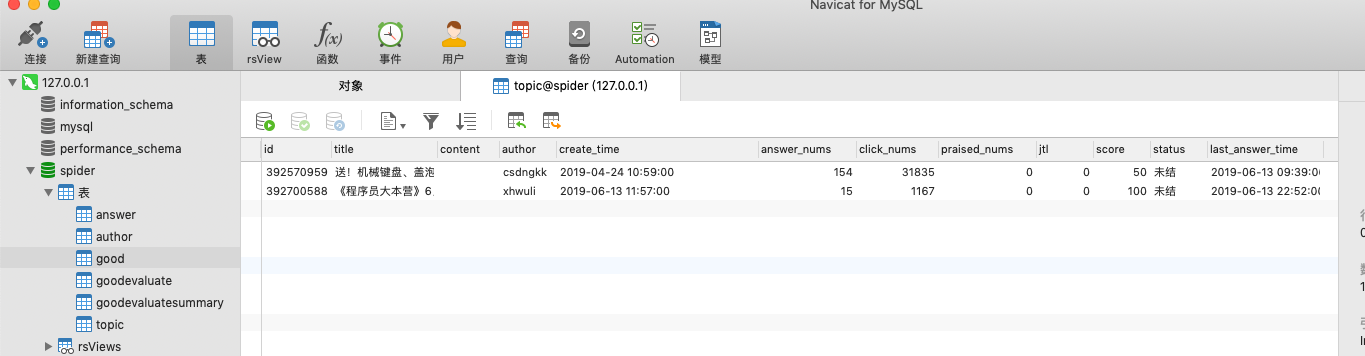
topic_url = parse.urljoin(domain, tr.xpath(".//td[3]/a[2]/@href").extract()[0])
IndexError: list index out of range
该如何解决这个问题,有知道吗?还请告知,万分感谢!
888
收起
正在回答
2回答


相似问题







登录后可查看更多问答,登录/注册





