关于utf-8解码问题?
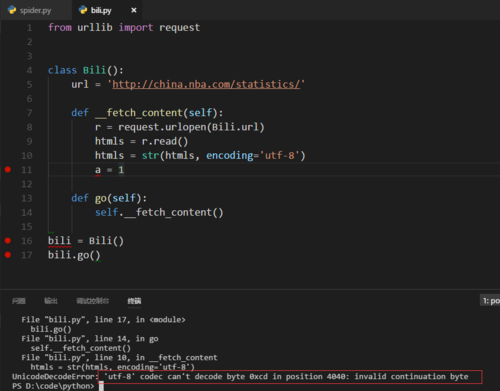
为什么有些url能运行和解码,有些url则报以上错误,尝试用那个chardet找出原始文档的编码,找不到,显示原始编码None,对编码解码的问题也是一知半解啊,不知道老师可否指点一下,只求知道原因,当然,如果能提供一些解决思路那就更好了啦,哈哈。(其实我弄了大半天都没解决,百度了一些解决方案,试过几个,都不行,主要是它有些URL页面是没问题的,可以顺利转换str和解码的,有些却不行,报以上错误,这点我很好奇,我个人的猜测:难道这就是传说中的反爬虫?他们这URL页面的编码的时候做了编码加密之类的动作?)
850
收起
正在回答
1回答

相似问题
响应数据已经指定了utf-8格式,但是得到的相应数据仍然为乱码
1664
4
10






关于 Unicode 的问题
1243
0
3


使用GET传参数出现中文乱码问题
1126
0
5




utf-8解码问题
41
1
4


GBK和UTF-8
1077
0
2
登录后可查看更多问答,登录/注册











