老师,快排,堆栈溢出了,!!!
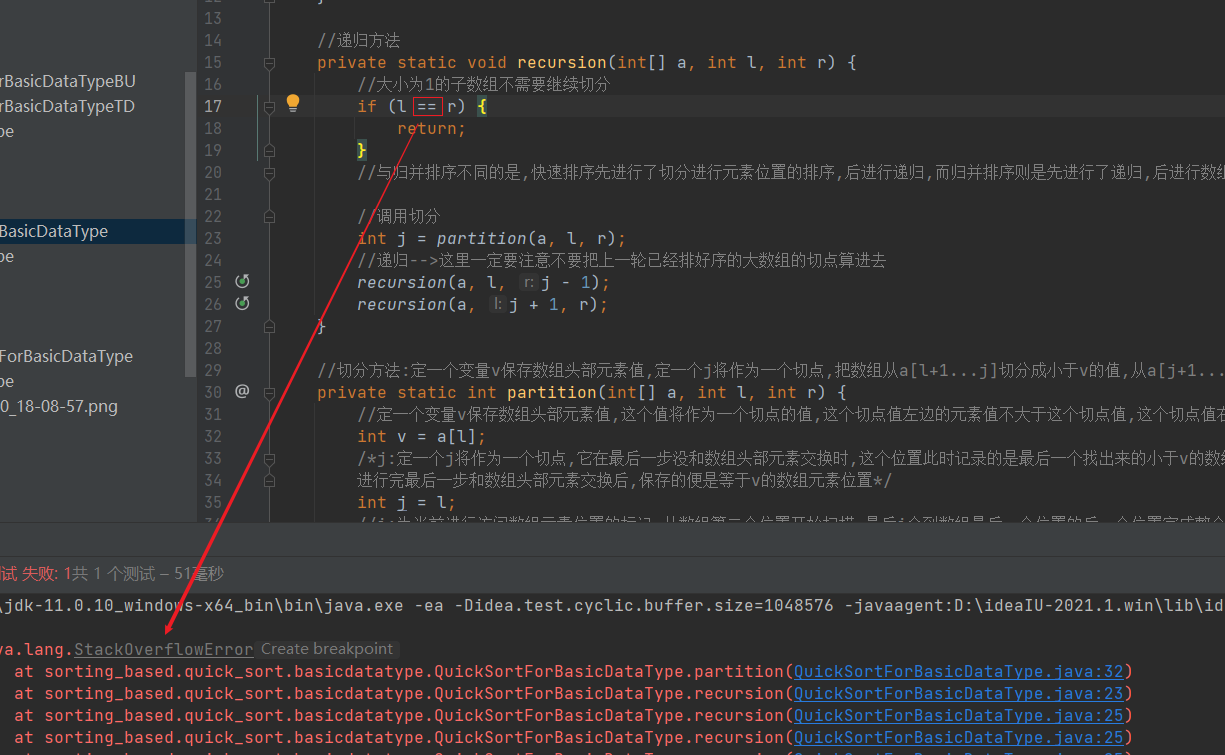
老师这里我写==和您写>=有什么区别嘛?我感觉都一样,所以我写了等等,然后就堆栈溢出了,这是无限递归了?
1074
收起
正在回答
3回答



相似问题
栈溢出
1307
0
2




堆排序栈溢出
1169
0
2
三路快排栈溢出了,老师可以帮我看看吗
1026
0
3


数组访问内存是通过栈访问堆吗?
1161
0
7
堆栈以及深拷贝的问题求老师解答
1040
2
7


登录后可查看更多问答,登录/注册








