为什么在我的电脑上运行快速排序要比归并排序要慢啊= =
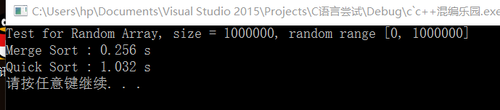
快速排序和归并排序(优化版)用的都是老师您的代码哦= =
基本上测试结果:
归并排序都是0.2左右
快速排序都是0.9左右
处理的数据规模是1000000
正在回答
7回答

liuyubobobo
2016-11-22 22:44:46
-
差距就这么大!加上随机化试试看。简单的一步,效率就比归并快了。随机化那一步是快速排序的精髓。不然快排无法保证递归深度是logn这个级别。关于快排的时间复杂度分析,由于这步随机化,所以准确的分析非常难,需要的数学知识太多了,我在课程中没有讲。你可以简单地理解:没有随机化,整个快排的递归树将严重有偏;而归并排序的递归树,则一定保持着深度是logn这个级别的。这也是我在回答中说:每次随机选取pivot,在真正的快排实现中“必须“加入。我强调“必须“的原因。
-
另外,这种“有偏“是测试用例相关的。如果递归树恰好不那么偏,快排就会表现的比较快。但要明白这种快是一种“侥幸”。不管怎样,随机化是快排中标准的步骤,让快排在统计意义上一跃成为最快的排序算法。必须加入。
点开查看后面4条评论

阳光的味道3821399
2017-01-12 17:18:39
我这边也是这样的问题,归并排序效率比快速排序效率高(见下图, 100w的随机数据):
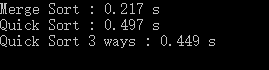
需要说明的是,我的代码中没有用标准库中的swap函数,因为效率更低,而是自己写了一个简单的交换函数
template<typename T>
void _swap(T &a, T &b) {
int tmp = a;
a = b;
b = tmp;
}// Quicksort, following Bentley and McIlroy,
// ``Engineering a Sort Function,'' SP&E November 1993.
上面这篇论文给出了cpu运算的执行时间,如下图

从图中可以看出,标准库里面的swap函数效率很低,是赋值50多倍,而即使是自己写的交换函数,效率也是比较低的。
归并排序中没有用到交换,而快排中主要操作就是交换,会不会是这个原因导致效率下降的呢?
-
liuyubobobo #1
就是这样的!赞研究精神。 不过自己写swap,会丧失编译器优化的性能。如果是使用VS做的实验,试试看在release模式下测试算法的性能?具体见这个问题: http://coding.imooc.com/learn/questiondetail/3603.html
-
liuyubobobo #2
如果使用VS做算法性能测试,请确保是在release模式下运行哦。具体可以看这个问题:http://coding.imooc.com/learn/questiondetail/3603.html


keyboard2steper
2017-02-11 21:05:50
-
liuyubobobo #1
如果使用VS做算法性能测试,请确保是在release模式下运行哦。具体可以看这个问题:http://coding.imooc.com/learn/questiondetail/3603.html

#include<stdio.h>
#include<iostream>
#include<stdlib.h>
#include<time.h>
#include"SortTestHelper.h"
#define True 1
template<typename T>
void insertionSort(T arr[], int l, int r) {
for (int i = l + 1; i <= r; i++) {
T e = arr[i];
int j;
for (j = i; j > l && arr[j - 1] > e; j--)
arr[j] = arr[j - 1];
arr[j] = e;
}
return;
}
//===================================================================
template<typename T>
void __merge(T arr[], int l, int mid, int r) {
T *aux=new T[r-l+1];
for (int i = l; i <= r; i++)
aux[i - l] = arr[i];
int i = l, j = mid + 1;
for (int k = l; k <= r; k++) {
if (i > mid) { arr[k] = aux[j - l]; j++; }
else if (j > r) { arr[k] = aux[i - l]; i++; }
else if (aux[i - l] < aux[j - l]) { arr[k] = aux[i - l]; i++; }
else { arr[k] = aux[j - l]; j++; }
}
delete[] aux;
}
template<typename T>
void __mergeSort(T arr[], int l, int r) {
if (r - l <= 15) {
insertionSort(arr, l, r);
return;
}
int mid = (l + r) / 2;
__mergeSort(arr, l, mid);
__mergeSort(arr, mid + 1, r);
if (arr[mid] > arr[mid + 1])
__merge(arr, l, mid, r);
}
template<typename T>
void mergeSort(T arr[], int n) {
__mergeSort(arr, 0, n - 1);
}
//=======================================================================
//是对arr[l...r]进行partition操作
//返回p,使得arr[l...p-1]<arr[p];arr[p+1]>arr[p]
template<typename T>
int __partition(T arr[], int l, int r)
{
swap(arr[l], arr[rand() % (r - l + 1) + l]);
T v = arr[l];
int j = l;
for (int i = l + 1; i <= r; i++)
if (v > arr[i])
swap(arr[++j], arr[i]);
swap(arr[j], arr[l]);
return j;
}
//对arr[l...r]部分进行快速排序
template<typename T>
void __quicksort(T arr[], int l, int r)
{
//if (l >= r)
// return;
if (r - l <16)
{
insertionSort(arr, l, r);
return;
}
int p = __partition(arr, l, r);
__quicksort(arr, l, p - 1);
__quicksort(arr, p + 1, r);
return;
}
//快速排序!
template<typename T>
void quick_sort(T arr[], int n)
{
srand((int)time(NULL));
__quicksort(arr, 0, n - 1);
}
//=============================================================
//是对arr[l...r]进行partition操作
//返回p,使得arr[l...p-1]<arr[p];arr[p+1]>arr[p]
template<typename T>
int __partition2(T arr[], int l, int r)
{
swap(arr[l], arr[rand() % (r - l + 1) + l]);
T v = arr[l];
//arr[l+1...i)部分小于v,arr(j...r]部分大于v
int i = l + 1, j = r;
while (True)
{
while (i <= r&&arr[i] < v)
i++;
while (j >= l + 1 && arr[j] > v)
j--;
if (i > j)
break;
swap(arr[i], arr[j]);
i++;
j--;
}
swap(arr[l], arr[j]);
return j;
}
//对arr[l...r]部分进行快速排序
template<typename T>
void __quicksort2(T arr[], int l, int r)
{
//if (l >= r)
// return;
if (r - l <16)
{
insertionSort(arr, l, r);
return;
}
int p = __partition2(arr, l, r);
__quicksort2(arr, l, p - 1);
__quicksort2(arr, p + 1, r);
return;
}
//快速排序!
template<typename T>
void quick_sort2(T arr[], int n)
{
srand((int)time(NULL));
__quicksort2(arr, 0, n - 1);
}
//测试快速排序和归并排序的运行速度
int main()
{
//int time = 0,avm=0,avq=0,avq2=0;
int *arr1, *arr2, *arr3;
int n = 1000000;
//while (time < 1000000)
//{
arr1 = SortTestHelper::generateRandomArray(n, 0, n);
arr2 = SortTestHelper::copyIntArray(arr1, n);
arr3 = SortTestHelper::copyIntArray(arr1, n);
/*Guibing_BU_sort(arr1, n);
quick_sort(arr2, n);*/
//快排若没有随机化则会退化到o(n**2)级的算法
SortTestHelper::testSort("merge sort", mergeSort, arr1, n);
SortTestHelper::testSort("quick sort", quick_sort, arr2, n);
SortTestHelper::testSort("quick sort2", quick_sort2, arr3, n);
delete[] arr1;
delete[] arr2;
delete[] arr3;
/*}*/
putchar('\n');
int swaptime = 100;
arr1 = SortTestHelper::generateNearlyOrderedArray(n, swaptime);
arr2 = SortTestHelper::copyIntArray(arr1, n);
arr3 = SortTestHelper::copyIntArray(arr1, n);
SortTestHelper::testSort("merge sort", mergeSort, arr1, n);
SortTestHelper::testSort("quick sort", quick_sort, arr2, n);
SortTestHelper::testSort("quick sort2", quick_sort2, arr3, n);
delete[] arr1;
delete[] arr2;
delete[] arr3;
putchar('\n');
n = 1000000;
arr1 = SortTestHelper::generateRandomArray(n, 0, 10);
//arr2 = SortTestHelper::copyIntArray(arr1, n);
arr3 = SortTestHelper::copyIntArray(arr1, n);
/*Guibing_BU_sort(arr1, n);
quick_sort(arr2, n);*/
//快排若没有随机化则会退化到o(n**2)级的算法
SortTestHelper::testSort("merge sort", mergeSort, arr1, n);
//SortTestHelper::testSort("quick sort", quick_sort, arr2, n);
SortTestHelper::testSort("quick sort2", quick_sort2, arr3, n);
delete[] arr1;
//delete[] arr2;
delete[] arr3;
putchar('\n');
putchar('\n');
system("pause");
}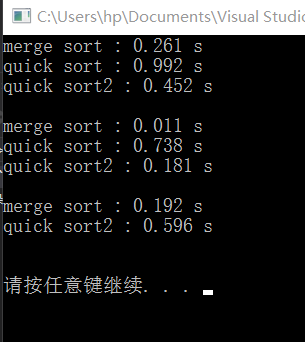
插入,归并,用的都是您的代码!
难道是我电脑有问题?
我有我舍友的电脑测试了下,运行结果甚至比我的更差!
-
liuyubobobo #1
我在mac下实验你的这段代码,结果如下。目测vs实现的编译器有坑。。。 我在windows下试试看。。。 merge sort : 0.427345 s quick sort : 0.302787 s quick sort2 : 0.300788 s merge sort : 0.122907 s quick sort : 0.205381 s quick sort2 : 0.119227 s merge sort : 0.258978 s quick sort2 : 0.148382 s
-
liuyubobobo #3
我在vs下试验了一下,也是这种问题,然后搞明白了。因为你是在debug模式下运行的程序,vs在debug模式下做了很多其他事情,主要集中在std中。快排使用了std::swap,我发现就是这个函数拖慢了速度。你测试一下,会发现自己写一个swap都比调用std::swap快。。。 但是如果你在release模式下运行程序,就不会有这些问题了!试试看!你的代码没有问题:) 赞!欢迎使用多语言实现这些算法!一定会有很大收获的:)

小狗和小猫咪30
2017-12-15 00:49:28
-
如果使用VS做算法性能测试,请确保是在release模式下运行哦。具体可以看这个问题:http://coding.imooc.com/learn/questiondetail/3603.html
老师我加上随机化了,但还是,改变不大
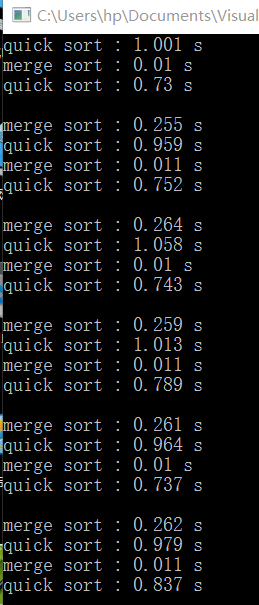
下面是源代码
#include<stdio.h>
#include<iostream>
#include<stdlib.h>
#include<time.h>
#include"SortTestHelper.h"
#include"Sort_collection.h"
using namespace std;
//是对arr[l...r]进行partition操作
//返回p,使得arr[l...p-1]<arr[p];arr[p+1]>arr[p]
template<typename T>
int __partition(T arr[], int l, int r)
{
swap(arr[l] , arr[rand() % (r - l + 1) + l]);
T v = arr[l];
int j = l;
for (int i = l + 1; i <= r; i++)
if (v > arr[i])
swap(arr[++j], arr[i]);
swap(arr[j], arr[l]);
return j;
}
//对arr[l...r]部分进行快速排序
template<typename T>
void __quicksort(T arr[], int l, int r)
{
//if (l >= r)
// return;
if (r - l <16)
{
charu_guibing_sort(arr, l, r);
return;
}
int p = __partition(arr, l, r);
__quicksort(arr, l, p - 1);
__quicksort(arr, p + 1, r);
return;
}
//快速排序!
template<typename T>
void quick_sort(T arr[],int n)
{
srand((int)time(NULL));
__quicksort(arr, 0, n - 1);
}
//测试快速排序和归并排序的运行速度
int main()
{
char c;
do {
int n = 1000000;
int *arr1 = SortTestHelper::generateRandomArray(n, 0, n);
int *arr2 = SortTestHelper::copyIntArray(arr1,n);
/*Guibing_BU_sort(arr1, n);
quick_sort(arr2, n);*/
//快排若没有随机化则会退化到o(n**2)级的算法
SortTestHelper::testSort("merge sort", Guibing_sort, arr1, n);
SortTestHelper::testSort("quick sort", quick_sort, arr2, n);
delete[] arr1;
delete[] arr2;
int swaptime = 100;
arr1 = SortTestHelper::generateNearlyOrderedArray(n, swaptime);
arr2 = SortTestHelper::copyIntArray(arr1, n);
SortTestHelper::testSort("merge sort", Guibing_sort, arr1, n);
SortTestHelper::testSort("quick sort", quick_sort, arr2, n);
delete[] arr1;
delete[] arr2;
} while ((c = getchar()) == '\n');
system("pause");
}-
liuyubobobo #1
我试了一下你的代码。其中的插入排序和归并排序用的我的代码,没有问题。检查一下你的charu_guibing_sort(arr, l, r)实现是否有问题? 你的这个程序和我的课程中这一小节的程序做的事情是一样的。运行一下我的代码,看看是不是也是这个结果? https://github.com/liuyubobobo/Play-with-Algorithms/tree/master/03-Sorting-Advance/06-Quick-Sort-Deal-With-Nearly-Ordered-Array
-
liuyubobobo #3
抱歉,我刚看到这个问题后来我就一直没有回复了。使用VS的同学,在做算法性能测试的时候,请一定使用Release模式运行程序!不然,VS会在Debug模式下的标准库中做一些其他事情,另外运行器也使用的是未优化的版本,从而拖慢算法的执行速度,使得算法性能的比较不准确。可以尝试测试一下,在VS Debug模式下,std::swap的速度非常慢,甚至比自己写的swap还要慢。而我们在归并排序中,没有使用std::swap,所以在debug模式下就会比快排还要快了。具体见这个问题: http://coding.imooc.com/learn/questiondetail/3603.html
相似问题
自底向上归并排序在2^n+1大小的数据集上是否性能会比较差?
1278
1
8

为何有递归的自顶向下的排序方法要快?
5443
35
6


为什么插入排序会远远由于归并排序?
1536
0
3
自底向上的归并排序的java代码问题
1809
0
6
快排的效率比其他的排序效率低
2931
9
3
登录后可查看更多问答,登录/注册
问题已解决,确定采纳
还有疑问,暂不采纳








