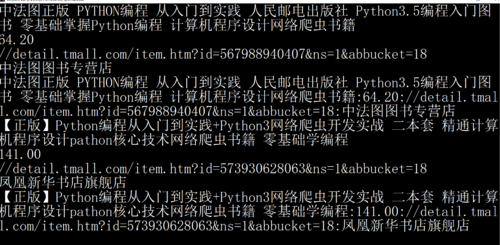
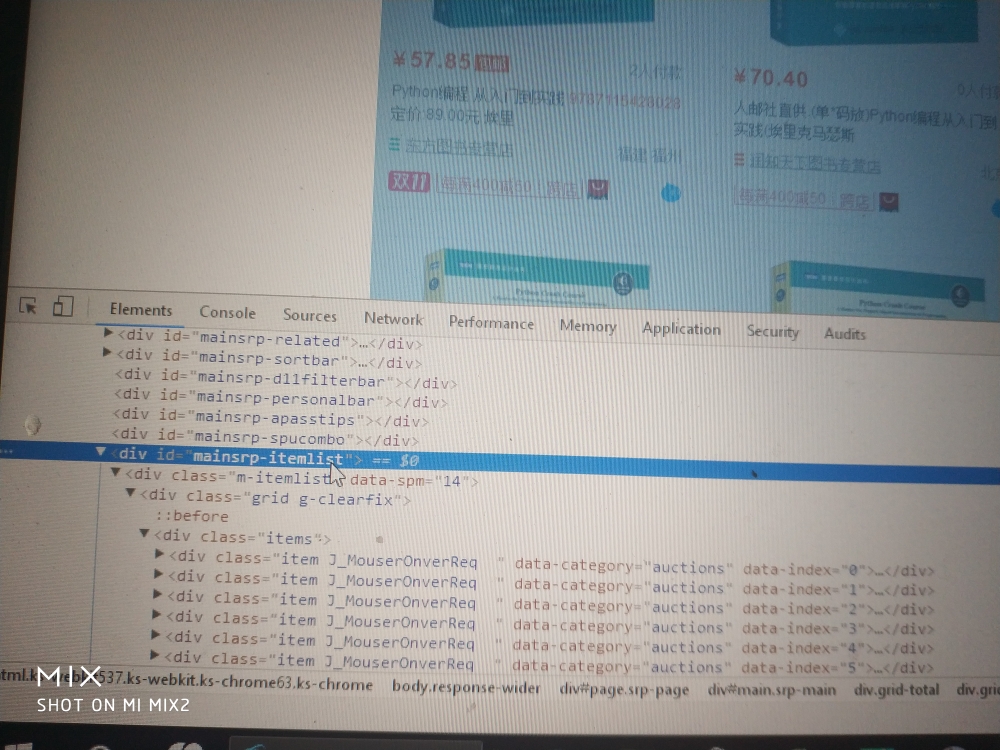
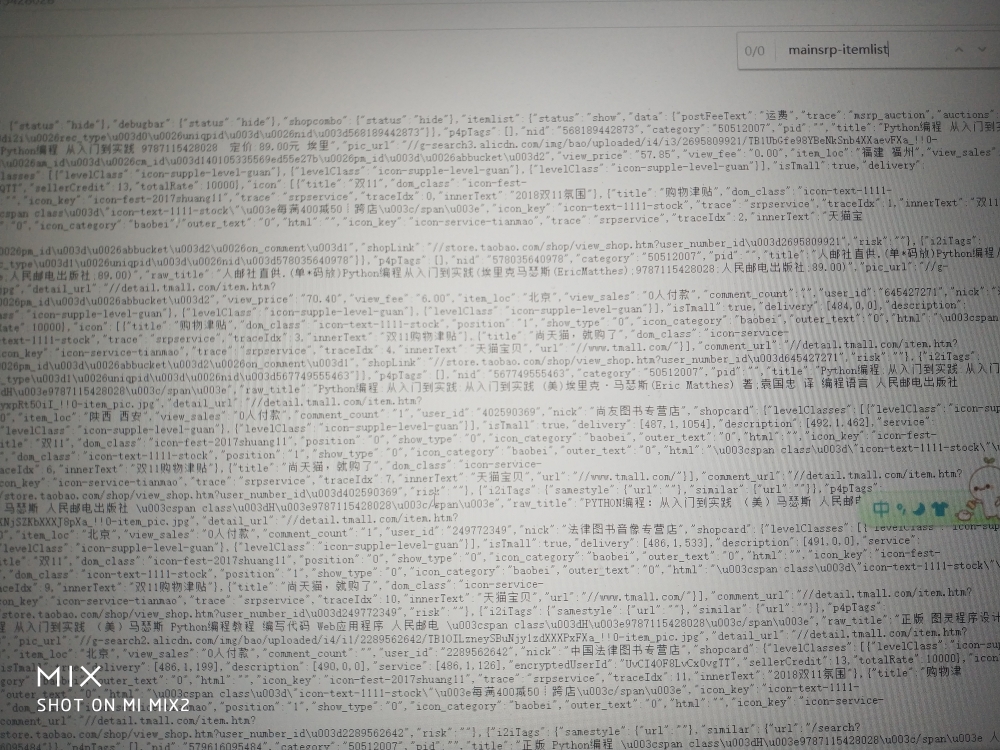
双11淘宝进行了较大的更新,使用正则实现淘宝数据抓取代码参考:
1.浏览器登录淘宝
2.按下图找到cookie
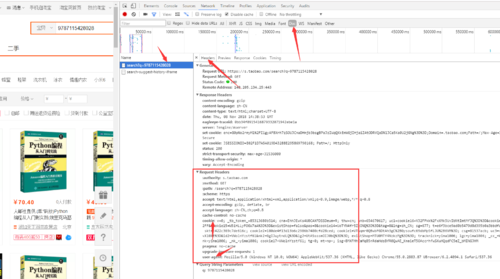
3.配置请求头信息
import requests
import re
import json
def spider_tb(sn ,book_list=[]):
url = 'https://s.taobao.com/search?q={0}'.format(sn)
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
'cookie': '你的cookie'
}
# 获取html内容
text = requests.get(url, headers=headers).text
# 使用正则表达式找到json对象
p = re.compile(r'g_page_config = (\{.+\});\s*', re.M)
rest = p.search(text)
if rest:
print(rest.group(1))
data = json.loads(rest.group(1))
bk_list = data['mods']['itemlist']['data']['auctions']
print (len (bk_list))
for bk in bk_list:
#标题
title = bk["raw_title"]
print(title)
#价格
price = bk["view_price"]
print(price)
#购买链接
link = bk["detail_url"]
print(link)
#商家
store = bk["nick"]
print(store)
book_list.append({ 'title' : title, 'price' : price, 'link' : link, 'store' : store })
print ('{title}:{price}:{link}:{store}'.format( title = title, price = price, link = link, store = store ))
if __name__ == '__main__':
spider_tb('9787115428028')4.查看结果