老师,如何往出循环每组数据?
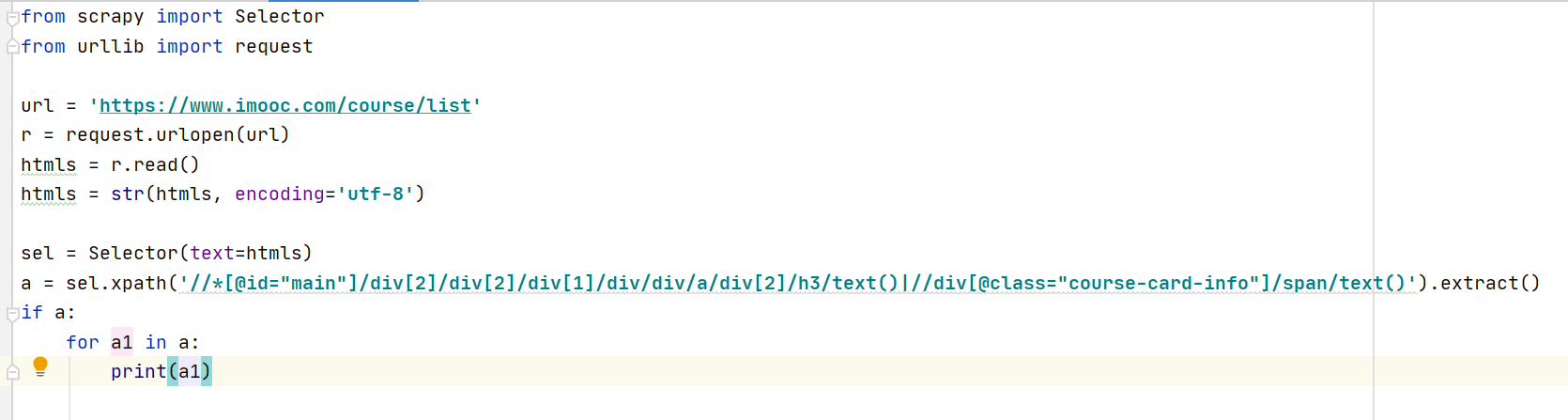
执行上面的代码返回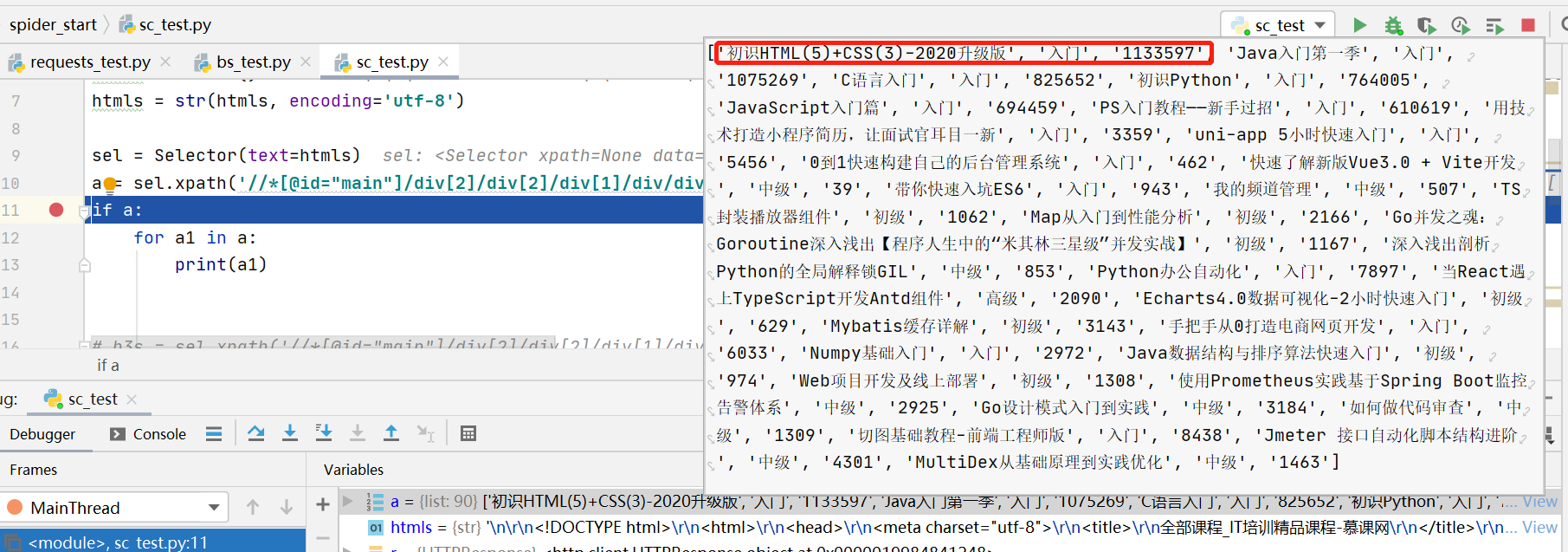
老师,我这个为什么不是一组一组的数据,而是把所有数据都put到了一个list里面,我是想要类似于下面这样的数据
[
[初识HTML(5)+CSS(3)-2020升级版,入门,1133597],
[Java入门第一季,入门,1075269]
]
代码如下:
from scrapy import Selector
from urllib import request
url = 'https://www.imooc.com/course/list’
r = request.urlopen(url)
htmls = r.read()
htmls = str(htmls, encoding=‘utf-8’)
sel = Selector(text=htmls)
a = sel.xpath(’//*[@id=“main”]/div[2]/div[2]/div[1]/div/div/a/div[2]/h3/text()|//div[@class=“course-card-info”]/span/text()’).extract()
if a:
for a1 in a:
print(a1)
from scrapy import Selector
from urllib import request
url = 'https://www.imooc.com/course/list'
r = request.urlopen(url)
htmls = r.read()
htmls = str(htmls, encoding='utf-8')
sel = Selector(text=htmls)
a = sel.xpath('//*[@id="main"]/div[2]/div[2]/div[1]/div/div/a/div[2]/h3/text()|//div[@class="course-card-info"]/span/text()').extract()
if a:
for a1 in a:
print(a1)
951
收起
正在回答
2回答

相似问题

addFirst(E e)=O(n)是如何计算出来的呢?
1157
0
4




如何将图片转换成mnist数据的格式
1812
0
5
377号组合数问题
1149
0
7


关于循环插入的问题
1067
0
6


登录后可查看更多问答,登录/注册





