正在回答
1回答
相似问题
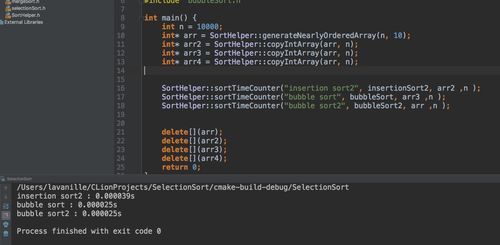
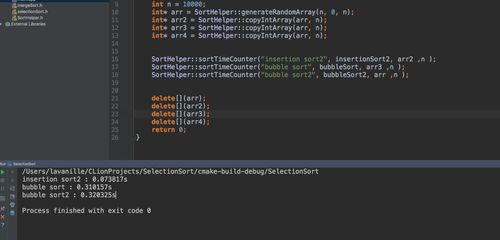
比较了冒泡排序和另外两种的花费时间,发现似乎没有任何优势?
1082
0
1


冒泡排序法及其改进版本
1368
0
2
手写冒泡排序
1429
0
4






冒泡排序
1413
0
1
选择排序的优化反而比原本的更慢了
1615
0
5
登录后可查看更多问答,登录/注册








