关于统一ID生成的探讨
比如聊天记录,订单等,用户量只要上去了,那么数据量就会增长得非常快。到后期就要面临分表的问题。个人设计了一下统一ID的方案,和老师探讨一下。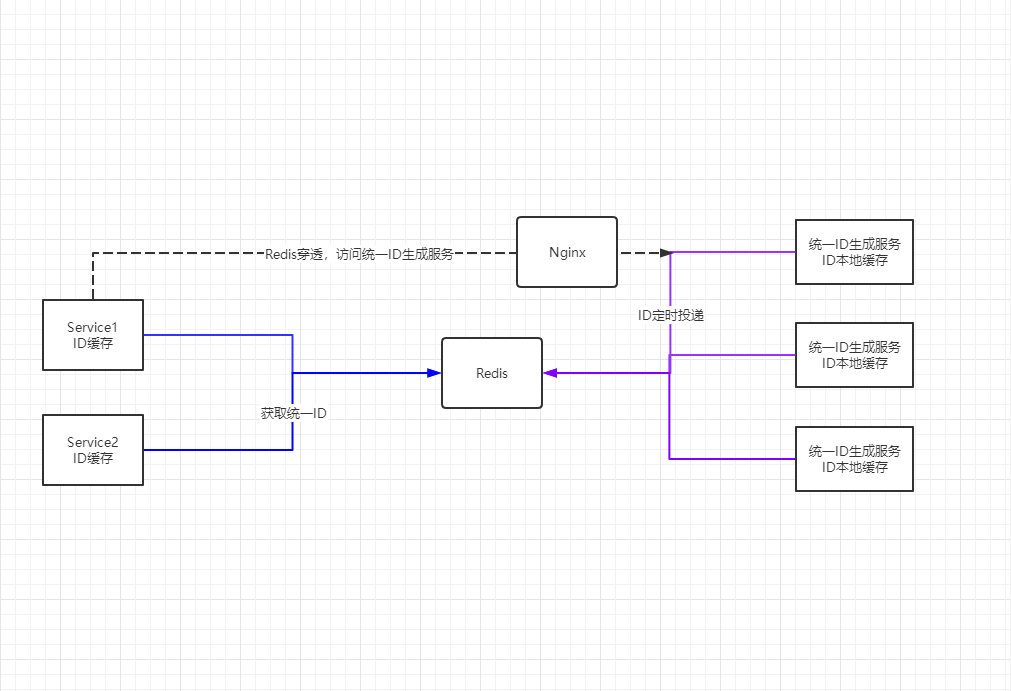
1.采用雪花算法作为ID生成策略,即时间戳+机器码+序列号
2.建立几个统一ID生成服务,采用定时任务的方式,每一段时间,判断一下Redis中的统一ID个数,如果为0或者低于某个阈值,就投放一批ID到Redis中。并且在启动的时候,也会提前生成好一批ID到内存中缓存起来,并定时监控,当内存中的ID数量低于某个阈值的时候,也对内存中的ID进行补充。
3.不同的业务Service,在启动的时候,也会从Redis中获取一批ID到内存中缓存起来,在需要用到ID的时候,首先从内存中获取,本地内存没有了再从Redis中获取。当然,Service也可以开启定时任务,定时扫描内存中可用ID数量,并进行补充。
4.如果Redis中的ID消耗完了,那么Service直接通过nginx代理访问到某一个具体的统一ID生成服务来获取ID。此时统一ID生成服务内存中如果有可用ID,直接返回内存中的ID。更极端点,这个统一ID生成服务的内存中也没有可用ID了,这时才会进行统一ID的生成,并返回。
5.雪花算法有个不好的地方就是NTP问题。我这里的解决思路有:
1):利用各种缓存(Redis,本地内存),提前存储好ID,拿来就用。在并发量不大的情况下,光靠缓存+定时补充就可以了。
2):缓存耗尽情况下,通过nginx访问到某一个统一ID生成服务生成ID的时候,发生NTP问题,直接返回异常,让请求再次转向另一台统一ID生成服务。一台机器NTP,另一台机器未必也时钟回拨了。
3):也可以在雪花算法的基础上,加上自增序列号,比如使用AtomicInteger,时间也许是回到过去了,但是自增序列号还是一直往前走的。
请一哥点评一下,谢谢一哥
正在回答
1回答

相似问题





登录后可查看更多问答,登录/注册







