调试后,关于IndexError: list index out of range的问题
这是我根据老师讲的和熊猫TV现在的HTML写的代码:
`import re
from urllib import request
class Spider():
url = 'https://www.panda.tv/cate/lol?pdt=1.24.s1.3.unl7kqgm1k’
root_pattern = '
([\s\S]?)
'name_pattern = '([\s\S.]?)'
number_pattern = ‘([\s\S.]*?)’
# 1
def __fetch_content(self):
r = request.urlopen(Spider.url)
htmls = r.read()
htmls = str(htmls, encoding='utf-8')
return htmls
# 2
def __analysis(self, htmls):
root_html = re.findall(Spider.root_pattern, htmls)
anchors = []
for html in root_html:
name = re.findall(Spider.name_pattern, html)
number = re.findall(Spider.number_pattern, html)
anchor = {'name':name, 'number':number}
anchors.append(anchor)
return anchors
# 3
def __refine(self, anchors):
l = lambda anchor: {
'name': anchor['name'][0].strip(),
'number': anchor['number'][0]
}
return map(l, anchors)
def go(self):
htmls = self.__fetch_content()
anchors = self.__analysis(htmls)
result_map = self.__refine(anchors)
result = list(result_map)
print(result)
spider = Spider()
spider.go()`
下面贴的是上段代码运行的结果: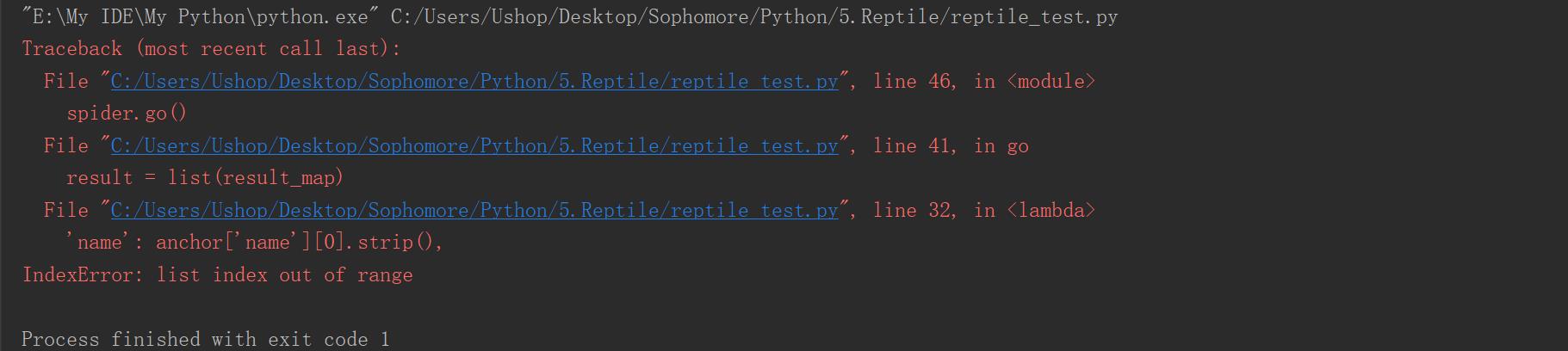
pycharm说的是lambda表达式那块有点问题,
然后我就把__refine(self, anchors)函数单独拿出来修改了一下,
用断点得到anchors的少量数据传到a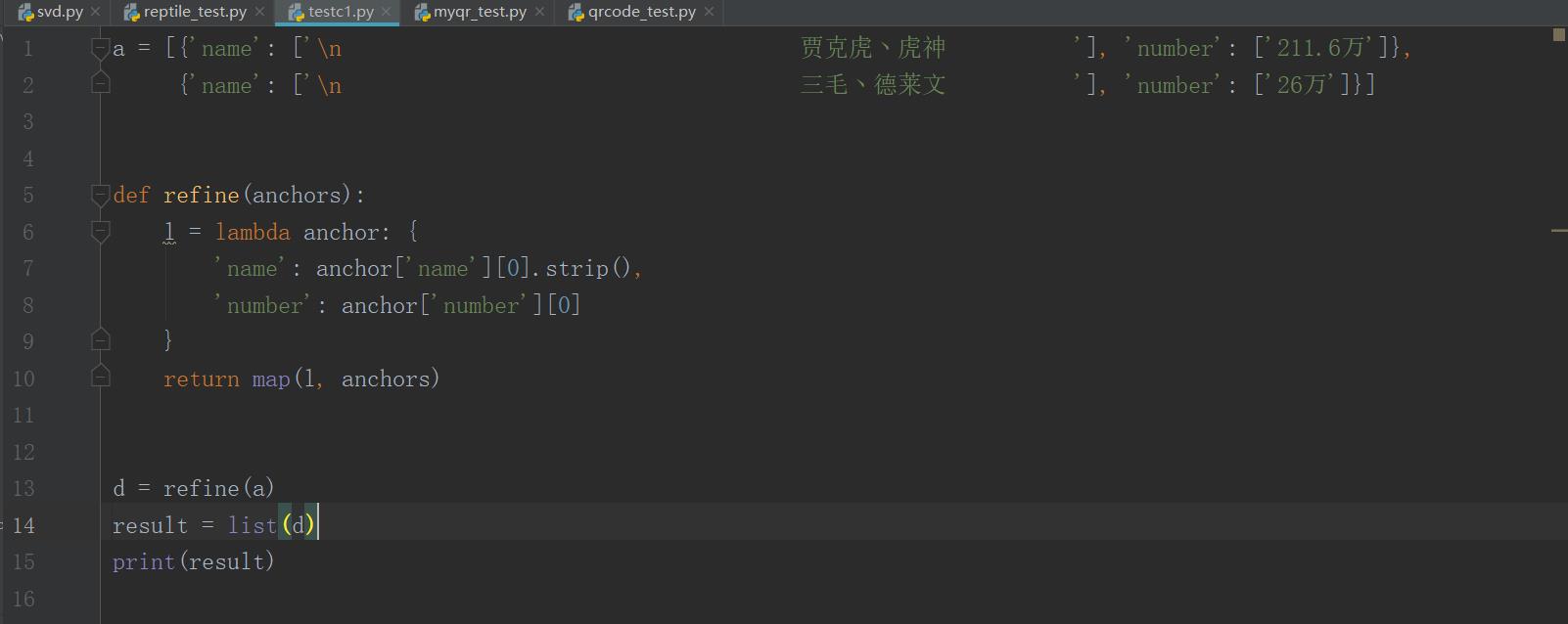 结果符合预期
结果符合预期
老师是什么原因导致这个IndexError: list index out of range?
anchors是没有问题的: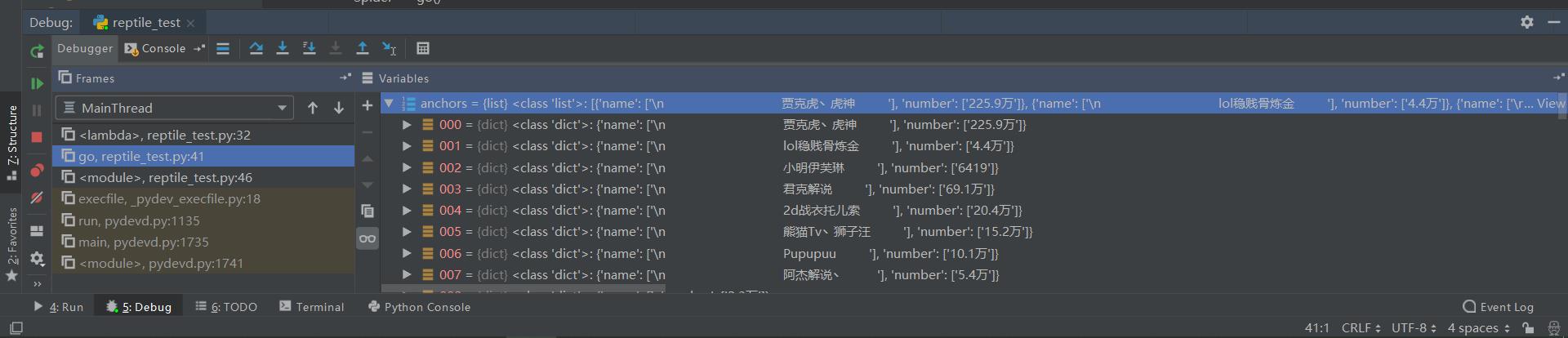
2414
收起
正在回答
3回答


相似问题
list index out of range
1401
0
2




"list index out of range"
878
0
1
IndexError: list index out of range
1870
0
2


IndexError: list index out of range
1216
0
7




登录后可查看更多问答,登录/注册











