采纳答案成功!
向帮助你的同学说点啥吧!感谢那些助人为乐的人
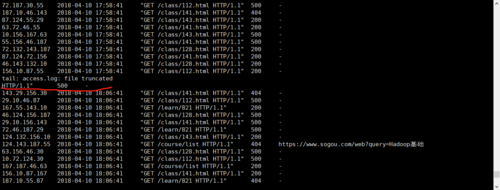
运行用python写的日志生成器,有kafka消费时会在控制台中会输出一些结构不完整的日志,用tail命令也会出现
那上面有一句话 tail file truncate的了。 这种即使不规范,那在sparkstreaming对接后,自己etl清洗掉不符合格式要求的日志就可以了
日志不规整很正常,生产上很多都是脏的,进去处理引擎后自己把脏数据丢了就行
我查出原因了,python文件每次输出100条日志,但是kafka或者tail不会输出所有日志,是从中间某个位置开始输出,所以每次输出时,第一条日志就会不完整。请问这种问题正常吗
不管啥都是正常的,在处理的时候肯定是要过滤的
这种情况你是咋处理的?
登录后可查看更多问答,登录/注册
Flume+Kafka+Spark Streaming 构建通用实时流处理平台
2.2k 89
1.7k 14
2.8k 13
2.4k 12
3.0k 12
购课补贴联系客服咨询优惠详情
慕课网APP您的移动学习伙伴
扫描二维码关注慕课网微信公众号