使用通义千问模型 ”qwen-omni-turbo“ 报错 url error, please check url!
我已经按照其模型文档 https://help.aliyun.com/zh/model-studio/qwen-omni?spm=5176.28197581.d_model-market.1.76ee5a9epToCb8#91de14b79ei05 进行了配置,以下是代码,其中base64_image就是‘z2021.pdf’的第11页,生成base64的代码也是课程中的源代码:
我使用官方示例代码把 base64_image 替换成课程中可以运行,但使用如下方式则会报错:
# 定义LLM
from langchain_openai import ChatOpenAI
from langchain_community.chat_models import ChatTongyi
import os
llm = ChatTongyi(
api_key=os.environ["QWEN_API_KEY"],
temperature=0.3,
base_url=os.environ["QWEN_API_BASE_URL"],
model="qwen-omni-turbo", # 此处以qwen-plus为例,您可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/getting-started/models
max_retries=3,
# 设置输出数据的模态,当前支持两种:["text","audio"]、["text"]
modalities=["text", "audio"],
audio={"voice": "Cherry", "format": "wav"},
stream=True,
stream_options={"include_usage": True}
# stop="我" # 设置停止词
# other params...
)
from langchain_core.messages import HumanMessage
query = "一线城市消费占比有多少?"
message = HumanMessage(
content=[
{"type": "text", "text": query},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{base64_image}"},
},
],
)
response = llm.invoke([message])
print(response.content)
报错信息如下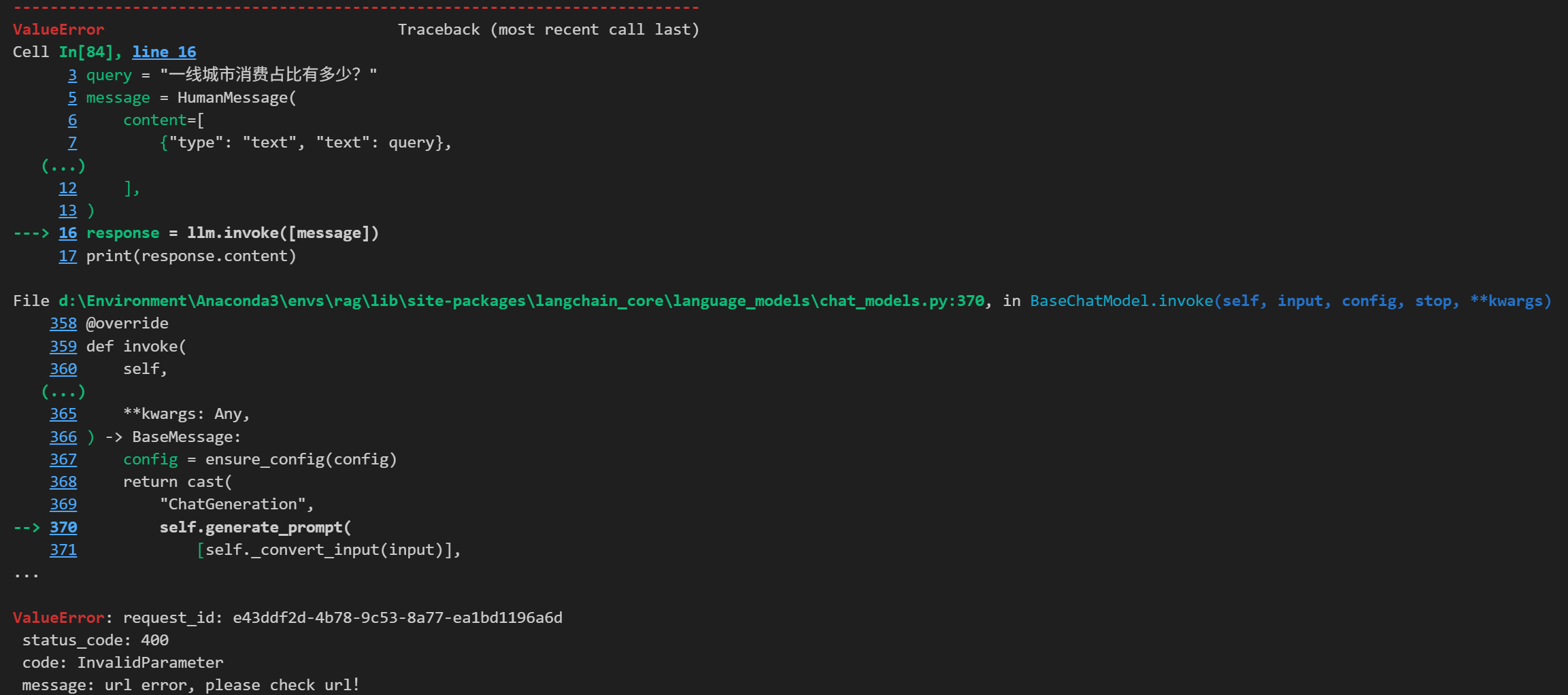
843
收起
正在回答
1回答

相似问题
启动报错,从网址下载了model.onnx还是报错
45
0
5




老师 spark 可以训练出url检测模型吗?大概什么思路呢?
1121
0
5


报url不存在
2078
0
13






通过router形成的url和直接配置的url有什么区别吗?
1353
0
4


关于url的一些问题
1132
0
2


登录后可查看更多问答,登录/注册




