老师,最大索引堆听不懂,听了1天,也没听懂怎么办?
老师我不知道为啥你用从数组1索引开始存堆内数据,这种堆做例子进行改进成为索引堆,这样不就没办法用之前从0索引开始存堆内数据直接在原数组中进行排序的优化了吗?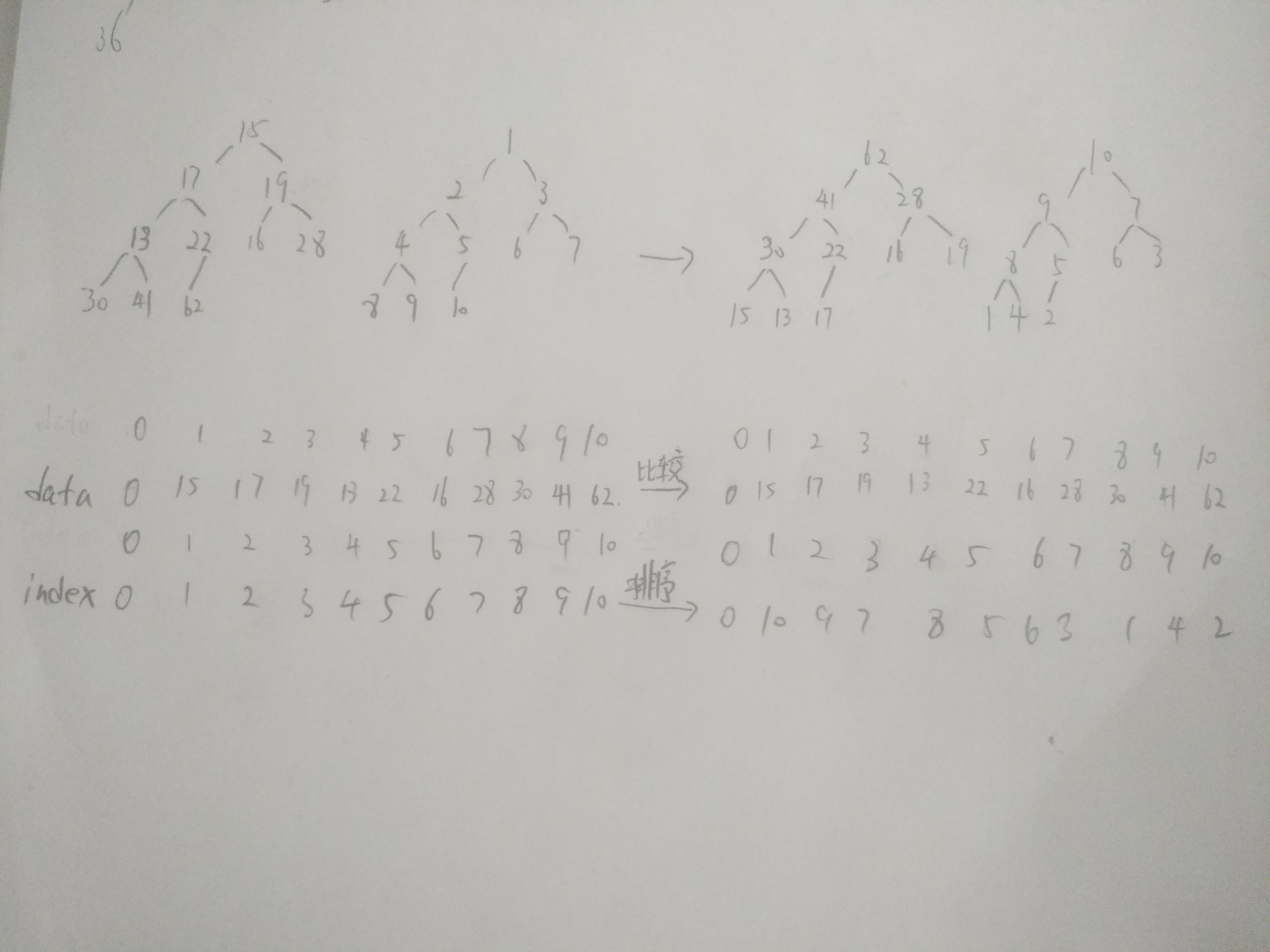
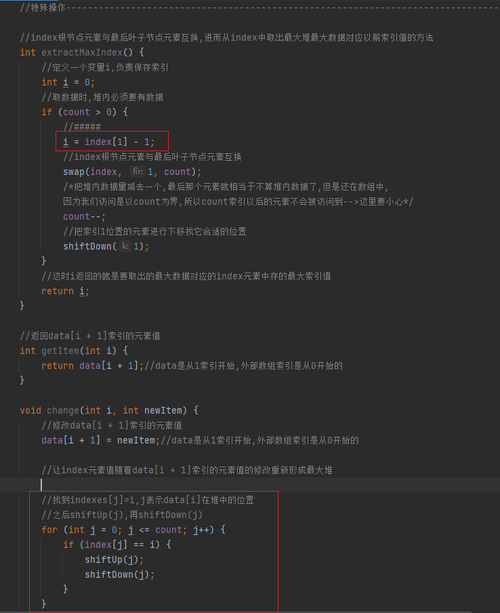
这是我对索引堆理解画的草图,索引堆就是实现用data中的堆内数据做比较,用index中存的data数组的索引值进行交换,其实data堆并没有动,动的只是index存的data的索引,这样就可以实现知道排好序的元素对应的原来data的索引,我怎么感觉这是个假的堆排序呢,而且代码有点太难了,局部变量太多,各种+1或-1,整不明白了,咋办老师
1286
收起
正在回答
2回答


相似问题
只有我一个人听不懂这个老师说话么?吐字不清全靠猜
1248
0
9






听不懂,不知道是我菜还是你菜
1165
3
7




Channel听不懂
1270
0
7


感觉好难听懂
1598
1
10




这几章我感觉怎么在听天书
719
0
4


登录后可查看更多问答,登录/注册








