词频统计的reduce个数
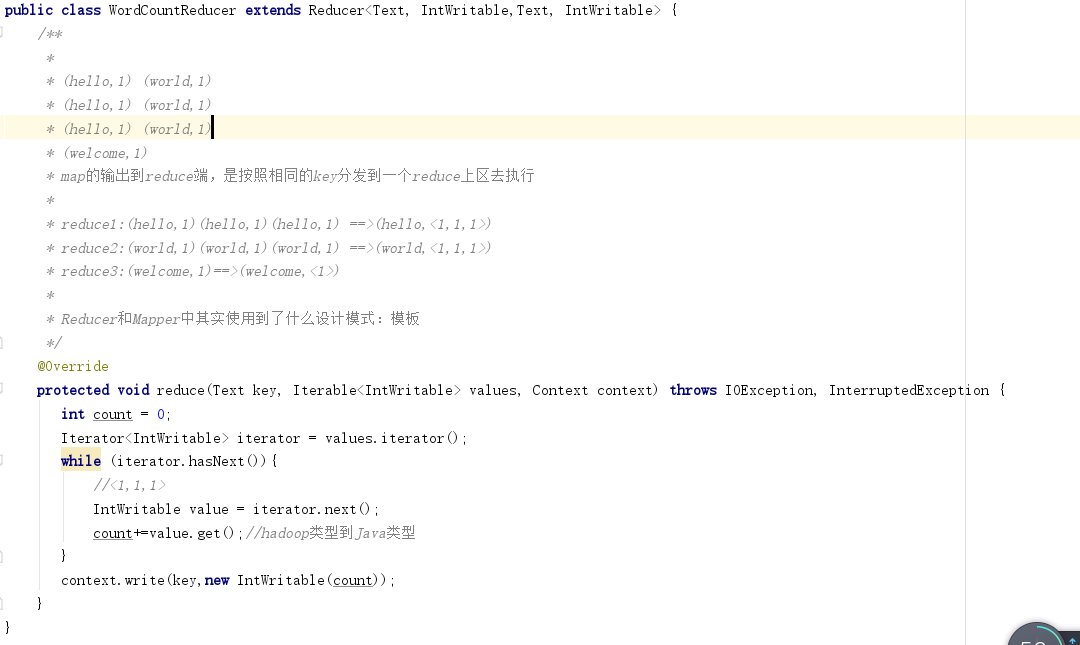
老师我们这里没有自定义Partitioner,那么我们通过默认的return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks来定义分区数来将key相同的map转发到不同分区进行处理,按道理返回应该不止一个分区为啥输出的文件是一个呢,难道return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks这个默认计算出来的值都是一样的?我在JDK源码debug没有debug出来。
745
收起













