xpath正确但是返回列表是空怎么回事?
老师您能不能运行一下我下面的代码,html返回没有问题,有我需要提取的数据,而且我的xpath在XPath Helper
中验证过了,是正确的,可以提取到数据,但是为什么用代码抓取下来的列表就是空的?但是在代码中改用相对路径’//*[@href="/topics/396730744"]'就可以获取到数据,这两个xpath一个绝对路径一个相对路径,在插件中验证都是没问题的,但是不明白为什么只有相对路径的可以提取到数据。
from scrapy import Selector
import requests
res = requests.get(‘https://bbs.csdn.net/’,verify=False)
html = res.text
print html
sel = Selector(text=html)
t = sel.xpath(’/html/body/div[3]/div[2]/div[1]/div[3]/ul/li[8]/label/a[2]/text()’).extract()
print t
2878
收起
正在回答 回答被采纳积分+3
2回答


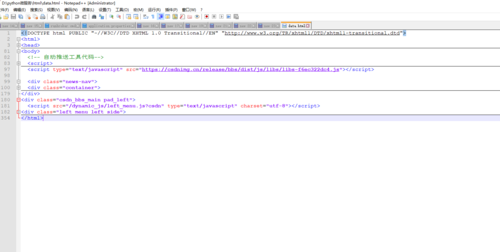 你应该像我这样 直接看html代码 你仔细俺看看这个路径中绝对路径对不对 我这里看起来是是不对的
你应该像我这样 直接看html代码 你仔细俺看看这个路径中绝对路径对不对 我这里看起来是是不对的相似问题
debug没报错 但是itemloader没有抓取到value值
1382
0
6


登录成功返回详情页中 后 点击返回时 会跳转到user页面
1838
0
3


下拉列表这部分怎么回事
805
0
4


返回的集合是空的
865
0
4


双击返回怎么实现呢?
925
0
4


登录后可查看更多问答,登录/注册





