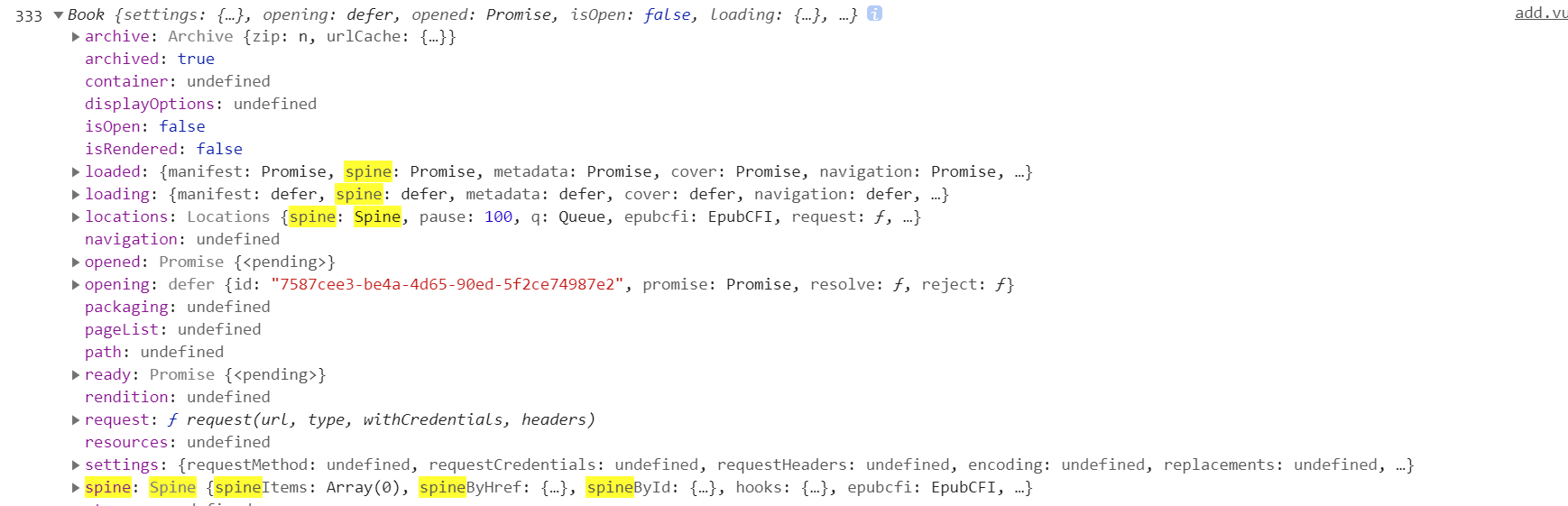
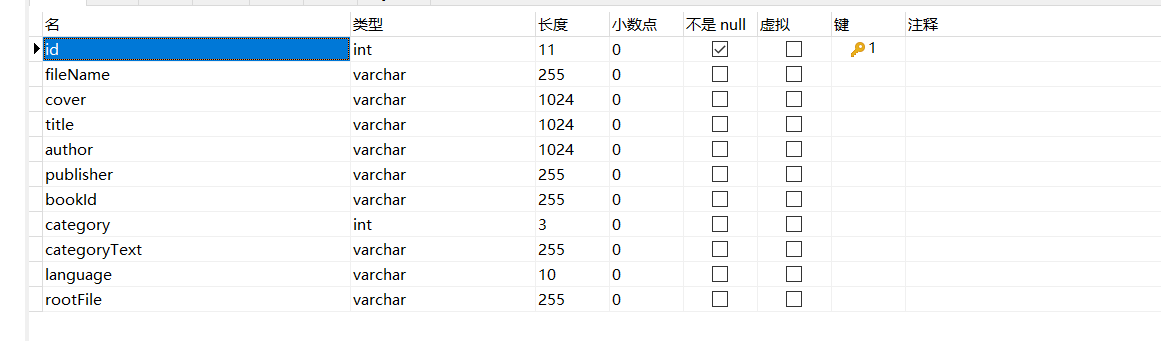
同学你好,你可以看一下小慕课读书中电子书提取代码,
const Epub = require('../utils/epub')
const fs = require('fs')
const xml2js = require('xml2js').parseString
const {
MIME_TYPE_EPUB,
UPLOAD_URL,
UPLOAD_PATH,
UPDATE_TYPE_FROM_WEB,
OLD_UPLOAD_URL
} = require('../utils/constant')
class Book {
constructor(file, data) {
if (file) {
this.createBookFromFile(file)
} else if (data) {
this.createBookFromData(data)
}
}
createBookFromFile(file) {
const {
destination: des, // 文件本地存储目录
filename, // 文件名称
mimetype = MIME_TYPE_EPUB // 文件资源类型
} = file
const suffix = mimetype === MIME_TYPE_EPUB ? '.epub' : ''
const oldBookPath = `${des}/${filename}`
const bookPath = `${des}/${filename}${suffix}`
const url = `${UPLOAD_URL}/book/${filename}${suffix}`
const unzipPath = `${UPLOAD_PATH}/unzip/${filename}`
const unzipUrl = `${UPLOAD_URL}/unzip/${filename}`
if (!fs.existsSync(unzipPath)) {
fs.mkdirSync(unzipPath, { recursive: true }) // 创建电子书解压后的目录
}
if (fs.existsSync(oldBookPath) && !fs.existsSync(bookPath)) {
fs.renameSync(oldBookPath, bookPath) // 重命名文件
}
this.fileName = filename // 文件名
this.path = `/book/${filename}${suffix}` // epub文件路径
this.filePath = this.path // epub文件路径
this.url = url // epub文件url
this.title = '' // 标题
this.author = '' // 作者
this.publisher = '' // 出版社
this.contents = [] // 目录
this.cover = '' // 封面图片URL
this.category = -1 // 分类ID
this.categoryText = '' // 分类名称
this.language = '' // 语种
this.unzipPath = `/unzip/${filename}` // 解压后的电子书目录
this.unzipUrl = unzipUrl // 解压后的电子书链接
this.originalName = file.originalname
}
createBookFromData(data) {
this.fileName = data.fileName
this.cover = data.coverPath
this.title = data.title
this.author = data.author
this.publisher = data.publisher
this.bookId = data.fileName
this.language = data.language
this.rootFile = data.rootFile
this.originalName = data.originalName
this.path = data.path || data.filePath
this.filePath = data.path || data.filePath
this.unzipPath = data.unzipPath
this.coverPath = data.coverPath
this.createUser = data.username
this.createDt = new Date().getTime()
this.updateDt = new Date().getTime()
this.updateType = data.updateType === 0 ? data.updateType : UPDATE_TYPE_FROM_WEB
this.contents = data.contents
}
parse() {
return new Promise((resolve, reject) => {
const bookPath = `${UPLOAD_PATH}${this.path}`
if (!this.path || !fs.existsSync(bookPath)) {
reject(new Error('电子书路径不存在'))
}
const epub = new Epub(bookPath)
epub.on('error', err => {
reject(err)
})
epub.on('end', err => {
if (err) {
reject(err)
} else {
// console.log('metadata', epub.metadata)
let {
title,
language,
creator,
creatorFileAs,
publisher,
cover
} = epub.metadata
// title = ''
if (!title) {
reject(new Error('图书标题为空'))
} else {
this.title = title
this.language = language || 'en'
this.author = creator || creatorFileAs || 'unknown'
this.publisher = publisher || 'unknown'
this.rootFile = epub.rootFile
const handleGetImage = (error, imgBuffer, mimeType) => {
if (error) {
reject(error)
} else {
const suffix = mimeType.split('/')[1]
const coverPath = `${UPLOAD_PATH}/img/${this.fileName}.${suffix}`
const coverUrl = `${UPLOAD_URL}/img/${this.fileName}.${suffix}`
fs.writeFileSync(coverPath, imgBuffer, 'binary')
this.coverPath = `/img/${this.fileName}.${suffix}`
this.cover = coverUrl
resolve(this)
}
}
try {
this.unzip() // 解压电子书
this.parseContents(epub)
.then(({ chapters, chapterTree }) => {
this.contents = chapters
this.contentsTree = chapterTree
epub.getImage(cover, handleGetImage) // 获取封面图片
})
.catch(err => reject(err)) // 解析目录
} catch (e) {
reject(e)
}
}
}
})
epub.parse()
this.epub = epub
})
}
unzip() {
const AdmZip = require('adm-zip')
const zip = new AdmZip(Book.genPath(this.path)) // 解析文件路径
zip.extractAllTo(
/*target path*/Book.genPath(this.unzipPath),
/*overwrite*/true
)
}
parseContents(epub) {
function getNcxFilePath() {
const manifest = epub && epub.manifest
const spine = epub && epub.spine
const ncx = manifest && manifest.ncx
const toc = spine && spine.toc
return (ncx && ncx.href) || (toc && toc.href)
}
/**
* flatten方法,将目录转为一维数组
*
* @param array
* @returns {*[]}
*/
function flatten(array) {
return [].concat(...array.map(item => {
if (item.navPoint && item.navPoint.length) {
return [].concat(item, ...flatten(item.navPoint))
} else if (item.navPoint) {
return [].concat(item, item.navPoint)
} else {
return item
}
}))
}
/**
* 查询当前目录的父级目录及规定层次
*
* @param array
* @param level
* @param pid
*/
function findParent(array, level = 0, pid = '') {
return array.map(item => {
item.level = level
item.pid = pid
if (item.navPoint && item.navPoint.length) {
item.navPoint = findParent(item.navPoint, level + 1, item['$'].id)
} else if (item.navPoint) {
item.navPoint.level = level + 1
item.navPoint.pid = item['$'].id
}
return item
})
}
if (!this.rootFile) {
throw new Error('目录解析失败')
} else {
const fileName = this.fileName
return new Promise((resolve, reject) => {
const ncxFilePath = Book.genPath(`${this.unzipPath}/${getNcxFilePath()}`) // 获取ncx文件路径
const xml = fs.readFileSync(ncxFilePath, 'utf-8') // 读取ncx文件
// 将ncx文件从xml转为json
xml2js(xml, {
explicitArray: false, // 设置为false时,解析结果不会包裹array
ignoreAttrs: false // 解析属性
}, function(err, json) {
if (!err) {
const navMap = json.ncx.navMap // 获取ncx的navMap属性
if (navMap.navPoint) { // 如果navMap属性存在navPoint属性,则说明目录存在
navMap.navPoint = findParent(navMap.navPoint)
const newNavMap = flatten(navMap.navPoint) // 将目录拆分为扁平结构
const chapters = []
epub.flow.forEach((chapter, index) => { // 遍历epub解析出来的目录
// 如果目录大于从ncx解析出来的数量,则直接跳过
if (index + 1 > newNavMap.length) {
return
}
const nav = newNavMap[index] // 根据index找到对应的navMap
chapter.text = `${UPLOAD_URL}/unzip/${fileName}/${chapter.href}` // 生成章节的URL
// console.log(`${JSON.stringify(navMap)}`)
if (nav && nav.navLabel) { // 从ncx文件中解析出目录的标题
chapter.label = nav.navLabel.text || ''
} else {
chapter.label = ''
}
chapter.level = nav.level
chapter.pid = nav.pid
chapter.navId = nav['$'].id
chapter.fileName = fileName
chapter.order = index + 1
chapters.push(chapter)
})
const chapterTree = []
chapters.forEach(c => {
c.children = []
if (c.pid === '') {
chapterTree.push(c)
} else {
const parent = chapters.find(_ => _.navId === c.pid)
parent.children.push(c)
}
}) // 将目录转化为树状结构
resolve({ chapters, chapterTree })
} else {
reject(new Error('目录解析失败,navMap.navPoint error'))
}
} else {
reject(err)
}
})
})
}
}
toJson() {
return {
path: this.path,
url: this.url,
title: this.title,
language: this.language,
author: this.author,
publisher: this.publisher,
cover: this.cover,
coverPath: this.coverPath,
unzipPath: this.unzipPath,
unzipUrl: this.unzipUrl,
category: this.category,
categoryText: this.categoryText,
contents: this.contents,
contentsTree: this.contentsTree,
originalName: this.originalName,
rootFile: this.rootFile,
fileName: this.fileName,
filePath: this.filePath
}
}
toDb() {
return {
fileName: this.fileName,
cover: this.cover,
title: this.title,
author: this.author,
publisher: this.publisher,
bookId: this.bookId,
updateType: this.updateType,
language: this.language,
rootFile: this.rootFile,
originalName: this.originalName,
filePath: this.path,
unzipPath: this.unzipPath,
coverPath: this.coverPath,
createUser: this.createUser,
createDt: this.createDt,
updateDt: this.updateDt,
category: this.category || 99,
categoryText: this.categoryText || '自定义'
}
}
getContents() {
return this.contents
}
reset() {
if (this.path && Book.pathExists(this.path)) {
fs.unlinkSync(Book.genPath(this.path))
}
if (this.filePath && Book.pathExists(this.filePath)) {
fs.unlinkSync(Book.genPath(this.filePath))
}
if (this.coverPath && Book.pathExists(this.coverPath)) {
fs.unlinkSync(Book.genPath(this.coverPath))
}
if (this.unzipPath && Book.pathExists(this.unzipPath)) {
// 注意node低版本将不支持第二个属性
fs.rmdirSync(Book.genPath(this.unzipPath), { recursive: true })
}
}
static genPath(path) {
if (path.startsWith('/')) {
return `${UPLOAD_PATH}${path}`
} else {
return `${UPLOAD_PATH}/${path}`
}
}
static pathExists(path) {
if (path.startsWith(UPLOAD_PATH)) {
return fs.existsSync(path)
} else {
return fs.existsSync(Book.genPath(path))
}
}
static genCoverUrl(book) {
if (Number(book.updateType) === 0) {
const { cover } = book
if (cover) {
if (cover.startsWith('/')) {
return `${OLD_UPLOAD_URL}${cover}`
} else {
return `${OLD_UPLOAD_URL}/${cover}`
}
} else {
return null
}
} else {
if (book.cover) {
if (book.cover.startsWith('/')) {
return `${UPLOAD_URL}${book.cover}`
} else {
return `${UPLOAD_URL}/${book.cover}`
}
} else {
return null
}
}
}
}
module.exports = Book