在遍历元素时xpath和css选择器为什么结果不一样
代码如下:
post_nodes = response.xpath('//div[@id="news_list"]/div[@class="news_block"]')
# post_nodes = response.css('#news_list .news_block')
for post_node in post_nodes:
# print(post_node)
image_url = post_node.xpath('//div[@class="entry_summary"]/a/img/@src').extract()
image_url = post_node.css('.entry_summary a img::attr(src)').extract()
用path结果如下: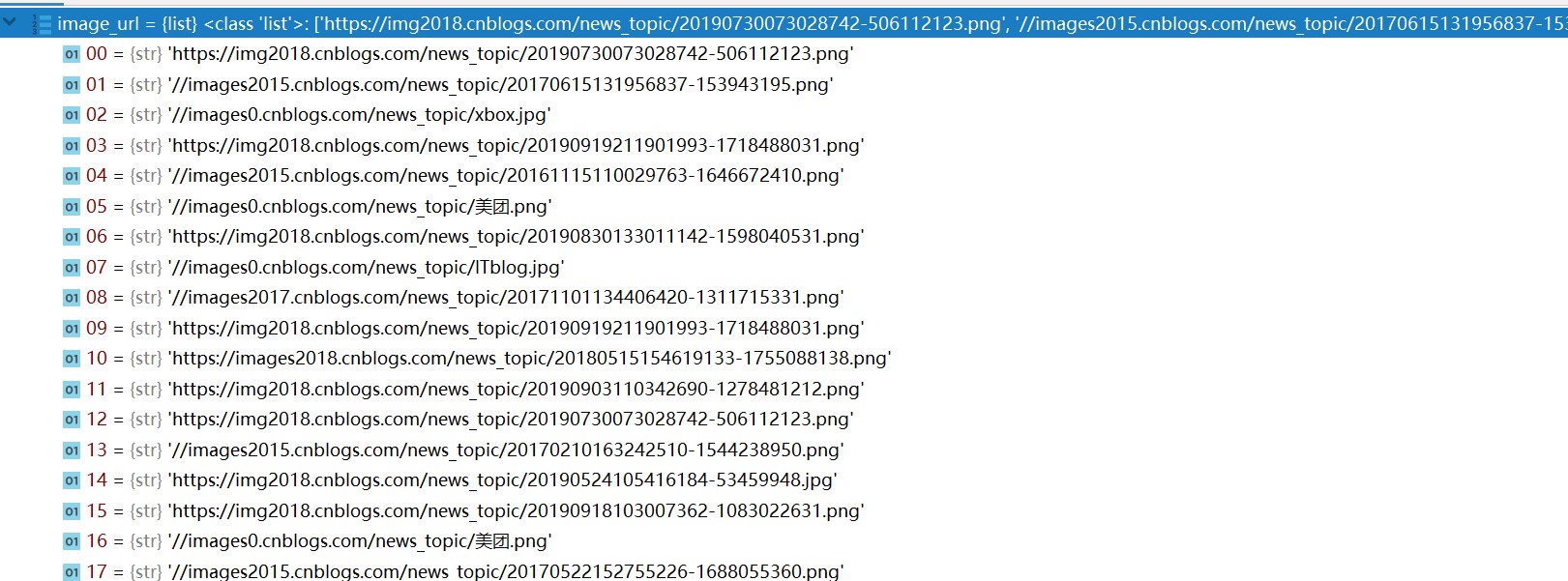
用css结果如下:
问题:
从结果分析是css正确的应该是每次遍历只能获取一个值
但是为什么用xpath却获取了所有的值,这明显是不对的
1103
收起
正在回答 回答被采纳积分+3
1回答
相似问题

请问css选择器和xpath有什么区别呢?
1256
0
2


关于二分搜索树的非递归遍历问题
1392
0
5


item_selecter的数据都是第一条的,怎么都跑不出下一条数据?
1038
0
3
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











