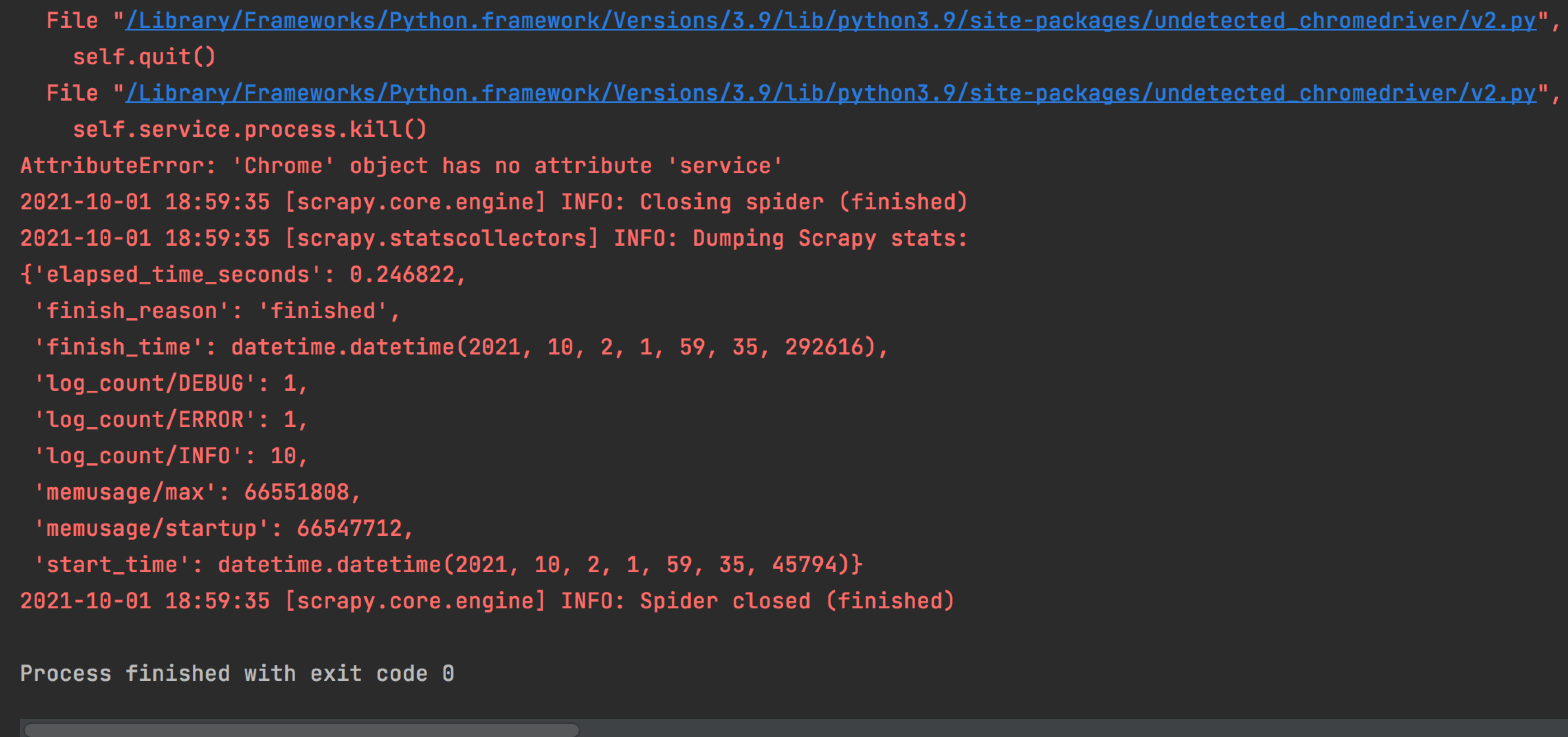
正在回答 回答被采纳积分+3
2回答
相似问题
selenium模拟知乎登陆的问题
1503
0
8


老师像美图那个登录要手机验证码的怎么解决啊
1485
0
3




为什么每次登陆后都自动跳转到“我的”webview?
1127
0
8


知乎模拟登陆
1067
0
1
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











