关键字检索出现了问题,断点调试发现两种检索的netloc不一样
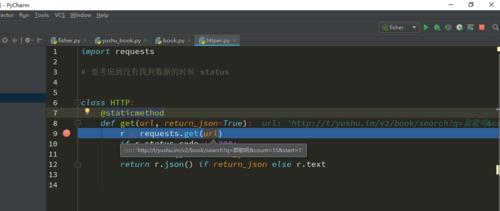
url是获取到了的,经过断点得知,错误在以下这步,代码执行到这步以后不会执行下面的r.status_code判断。也就是说request.get(url)没有返回值。
r = requests.get(url)
如果是ISBN检索的话是没有问题的,我分别进入了request.get中去看了下,分析了以下两者的区别:
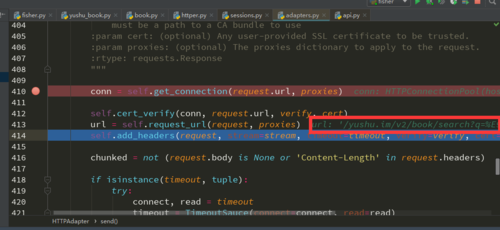
如果是关键字检索的话到最后url是'/yushu.im/v2/book/search?q=%E9%83%AD%E6%95%AC%E6%98%8E&count=15&start=1'
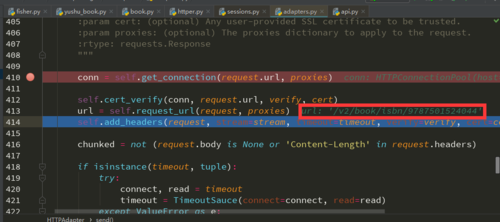
如果是ISBN检索的话url是'/v2/book/isbn/9787501524044'
一个前面有/yushu.im/,另一个则没有。进而导致了两种检索的netloc不一样,我以为不清楚问题是不是出在这个地方。
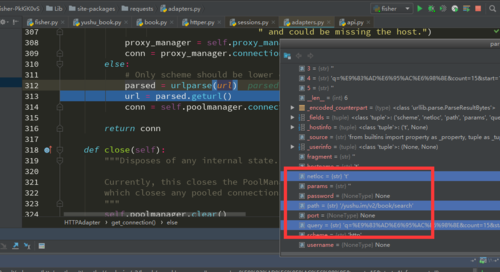
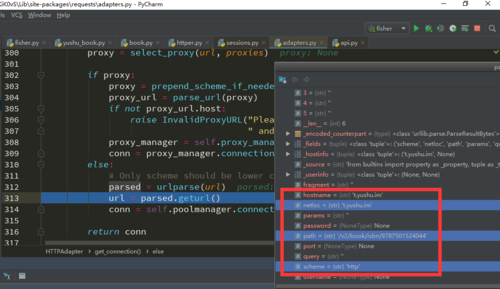
然后就会关键字检索就报了以下错误:
requests.exceptions.ConnectionError: HTTPConnectionPool(host='t', port=80): Max retries exceeded with url: /yushu.im/v2/book/search?q=%E9%83%AD%E6%95%AC%E6%98%8E&count=15&start=1 (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x000001A7761BD198>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed',))859
收起
正在回答 回答被采纳积分+3
1回答


相似问题
搜索
1369
0
8


多索引检索-父子文档,不同 embedding 模型意义
357
1
3


Spring Boot启动出现问题
1539
0
3


数值检索不准确
455
0
3


xdebug断点调试
1485
0
4




登录后可查看更多问答,登录/注册
Python Flask从0到1开发《鱼书》精品项目
- 参与学习 2786 人
- 提交作业 141 份
- 解答问题 1282 个
7月老师深入浅出剖析Flask核心机制,和你一起探讨Python高级编程
了解课程













