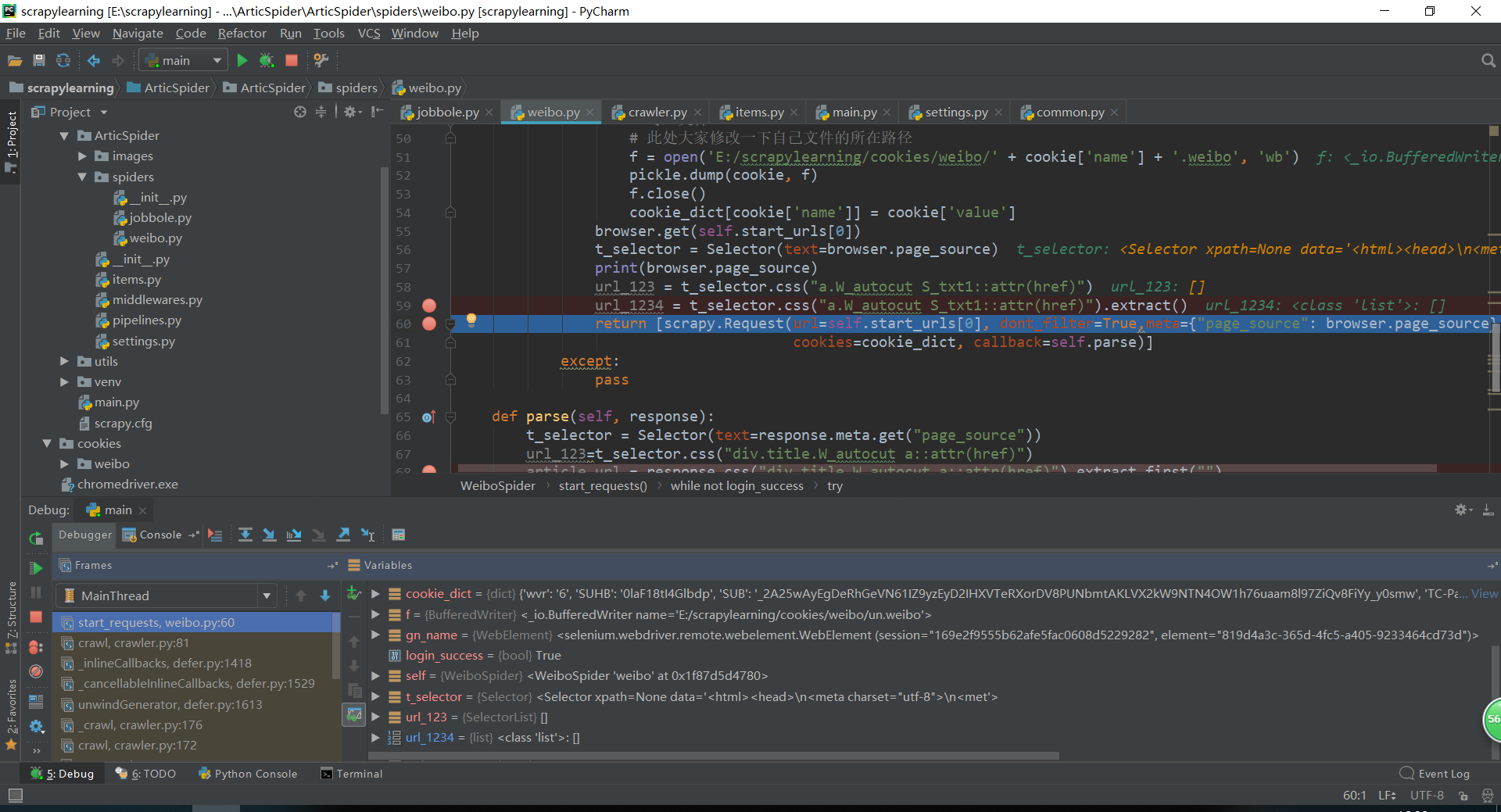
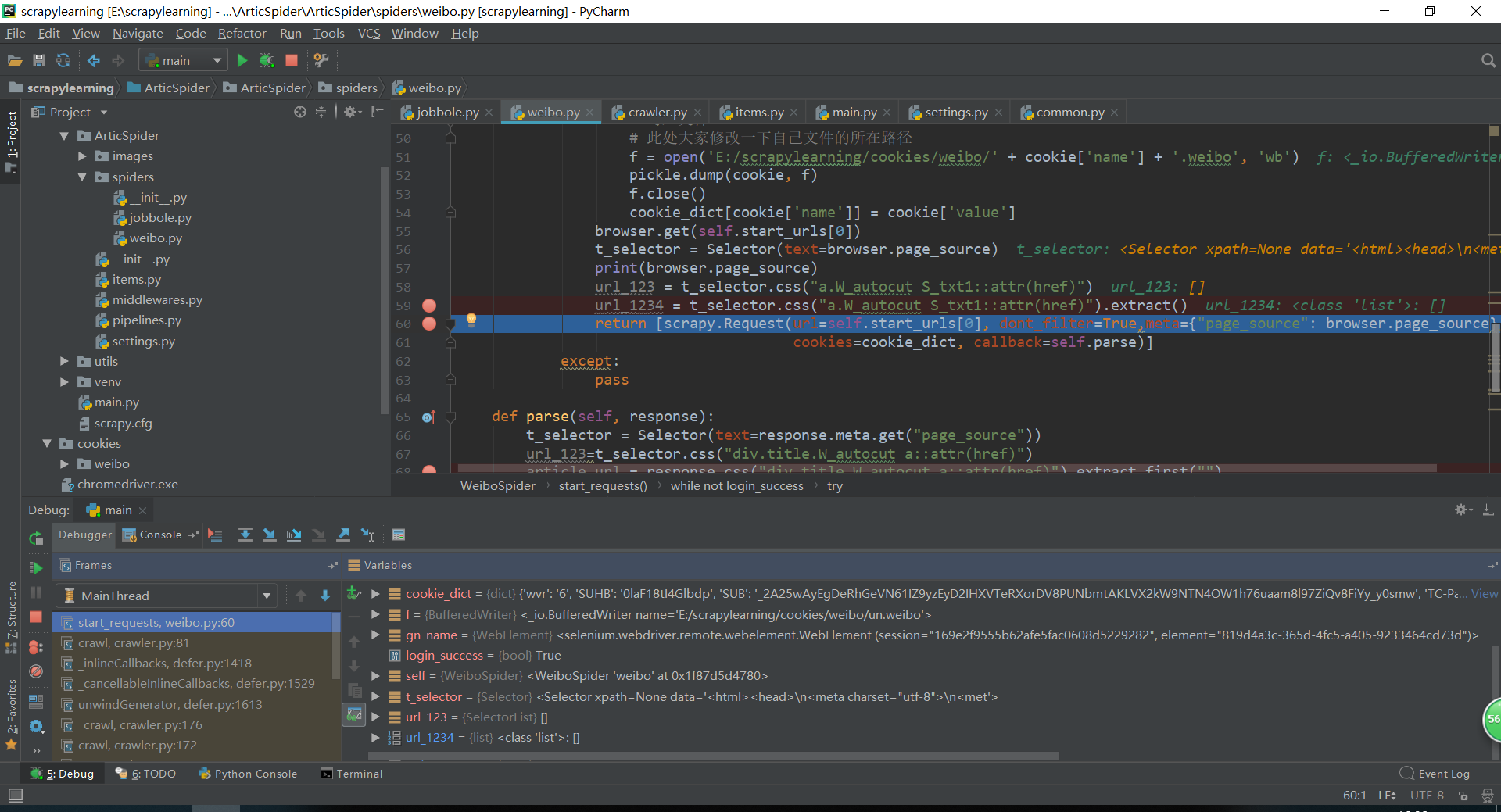
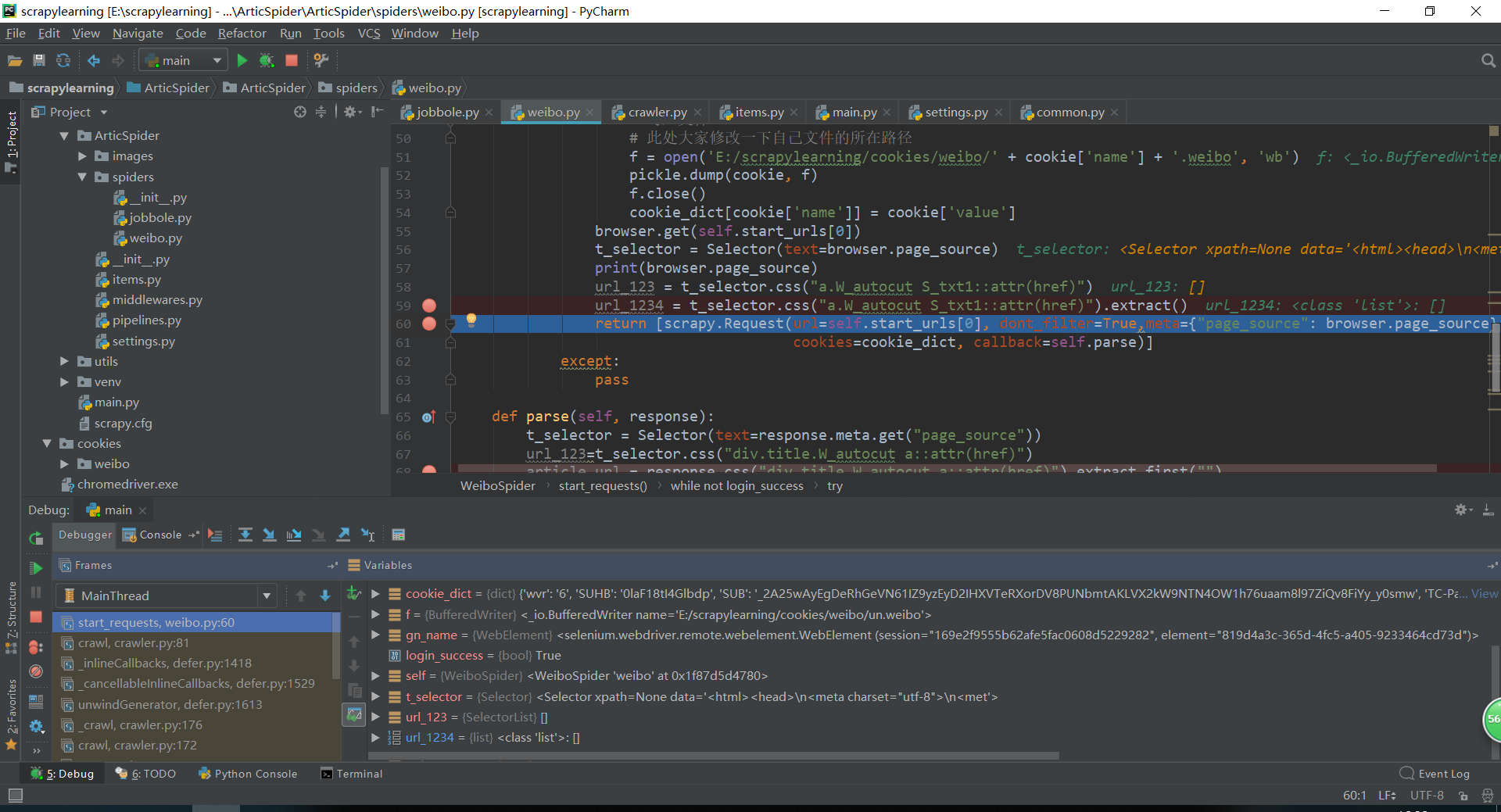
请问老师。提取不到url,网址https://d.weibo.com/623751_1/
start_urls = ['https://d.weibo.com/623751_1/']
browser.get(self.start_urls[0])
t_selector = Selector(text=browser.page_source)
print(browser.page_source)
url_123 = t_selector.css("a.W_autocut.S_txt1::attr(href)").extract()
```
1129
收起
正在回答 回答被采纳积分+3
3回答
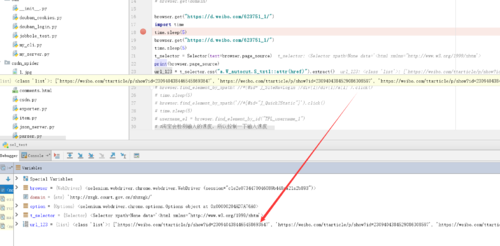 我刚才试了一下 能获取到啊 写法和你上面的写法一致:
我刚才试了一下 能获取到啊 写法和你上面的写法一致:相似问题
用xpath提取img src时会自动去掉https:是什么原因
848
0
3


可以把上课的笔记也上传到源码中吗?
1492
2
15







网盘无法访问了 可以发个新地址嘛
439
0
3


网络连接失败
1462
1
8




登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











