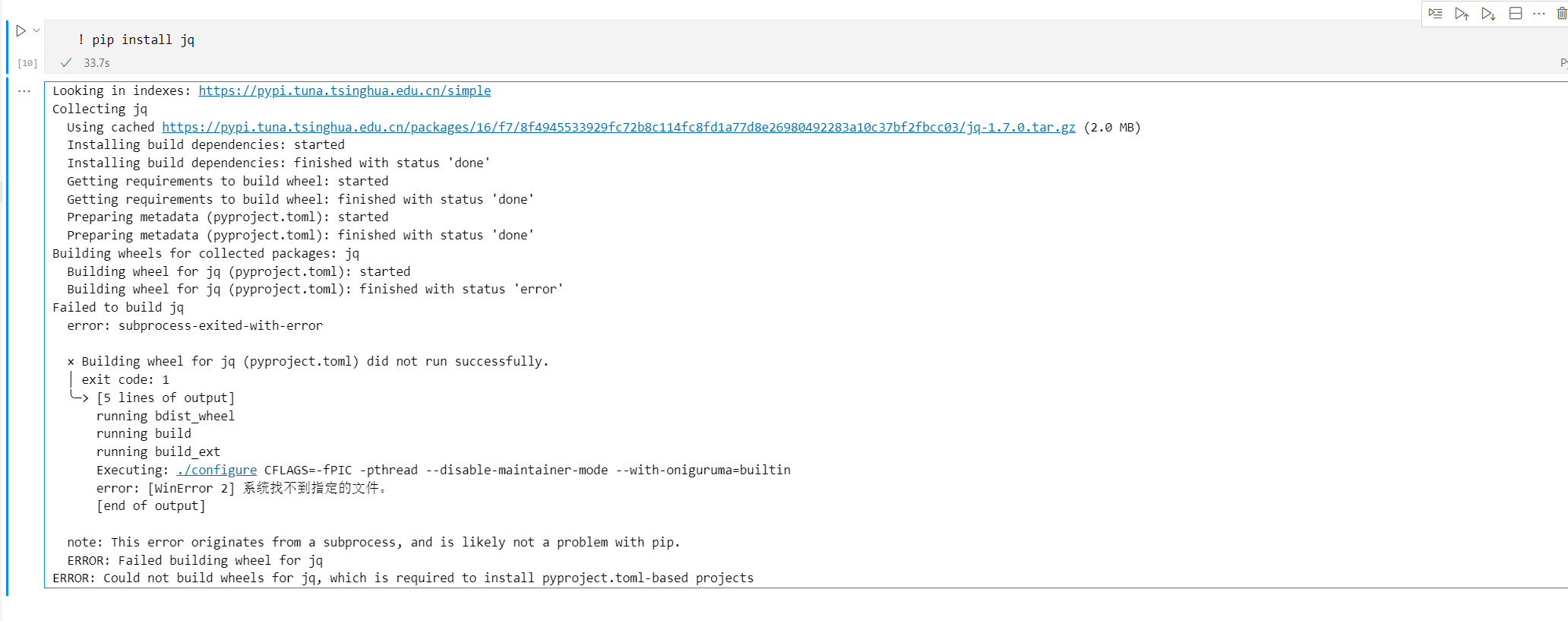
参考了老师提供官方的git里相似问题解法:https://github.com/langchain-ai/langchain/issues/4396,但是还有问题,根据报错信息,代码贴给了GPT-4,经过给出报错提示,修复了,代码如下:
import json
from pathlib import Path
from typing import Any, Callable, Dict, List, Optional, Union
from langchain.docstore.document import Document
from langchain.document_loaders.base import BaseLoader
class JSONLoader(BaseLoader):
def __init__(
self,
file_path: Union[str, Path],
content_key: Optional[str] = None,
metadata_func: Optional[Callable[[Dict, Dict], Dict]] = None,
text_content: bool = False,
json_lines: bool = False,
):
"""
Initializes the JSONLoader with a file path, an optional content key to extract specific content,
and an optional metadata function to extract metadata from each record.
"""
self.file_path = Path(file_path).resolve()
self._content_key = content_key
self._metadata_func = metadata_func
self._text_content = text_content
self._json_lines = json_lines
def load(self) -> List[Document]:
"""Load and return documents from the JSON file."""
docs: List[Document] = []
if self._json_lines:
with self.file_path.open(encoding="utf-8") as f:
for line in f:
line = line.strip()
if line:
self._parse(line, docs)
else:
self._parse(self.file_path.read_text(encoding="utf-8"), docs)
return docs
def _parse(self, content: str, docs: List[Document]) -> None:
"""Convert given content to documents."""
data = json.loads(content)
# 假设 data 是字典而不是列表
if isinstance(data, dict):
data = [data] # 将字典转换为单元素列表以便统一处理
# 确保 data 是列表
if not isinstance(data, list):
raise ValueError("Data is not a list!")
# 验证和处理每个记录
for i, sample in enumerate(data, len(docs) + 1):
text = self._get_text(sample=sample)
metadata = self._get_metadata(sample=sample, source=str(self.file_path), seq_num=i)
docs.append(Document(page_content=text, metadata=metadata))
def _get_text(self, sample: Any) -> str:
"""Convert sample to string format"""
if self._content_key is not None:
content = sample.get(self._content_key)
else:
content = sample
if self._text_content and not isinstance(content, str):
raise ValueError(
f"Expected page_content is string, got {type(content)} instead. \
Set `text_content=False` if the desired input for \
`page_content` is not a string"
)
# In case the text is None, set it to an empty string
elif isinstance(content, str):
return content
elif isinstance(content, dict):
return json.dumps(content) if content else ""
else:
return str(content) if content is not None else ""
def _get_metadata(self, sample: Dict[str, Any], **additional_fields: Any) -> Dict[str, Any]:
"""
Return a metadata dictionary base on the existence of metadata_func
:param sample: single data payload
:param additional_fields: key-word arguments to be added as metadata values
:return:
"""
if self._metadata_func is not None:
return self._metadata_func(sample, additional_fields)
else:
return additional_fields
def _validate_content_key(self, data: Any) -> None:
"""Check if a content key is valid, assuming data is a list of dictionaries."""
# Assuming data should be a list of dicts, we take the first dict to examine.
# Make sure to verify that data is list and it is not empty, and its elements are dicts.
if isinstance(data, list) and data:
sample = data[0]
if not isinstance(sample, dict):
raise ValueError(
f"Expected the data schema to result in a list of objects (dict), "
"so sample must be a dict but got `{type(sample)}`."
)
if self._content_key not in sample:
raise ValueError(
f"The content key `{self._content_key}` is missing in the sample data."
)
else:
raise ValueError("Data is empty or not a list!")
def _validate_metadata_func(self, data: Any) -> None:
"""Check if the metadata_func output is valid, assuming data is a list of dictionaries."""
if isinstance(data, list) and data:
sample = data[0]
if self._metadata_func is not None:
sample_metadata = self._metadata_func(sample, {})
if not isinstance(sample_metadata, dict):
raise ValueError(
f"Expected the metadata_func to return a dict but got `{type(sample_metadata)}`."
)
else:
raise ValueError("Data is empty or not a list!")
def item_metadata_func(record: dict, metadata: dict) -> dict:
# metadata["_type"] = record.get("_type")
metadata["input_variables"] = record.get("input_variables")
metadata["template"] = record.get("template")
return metadata
loader = JSONLoader(file_path='simple_prompt.json', content_key='description', metadata_func=item_metadata_func)
data = loader.load()
print(data)