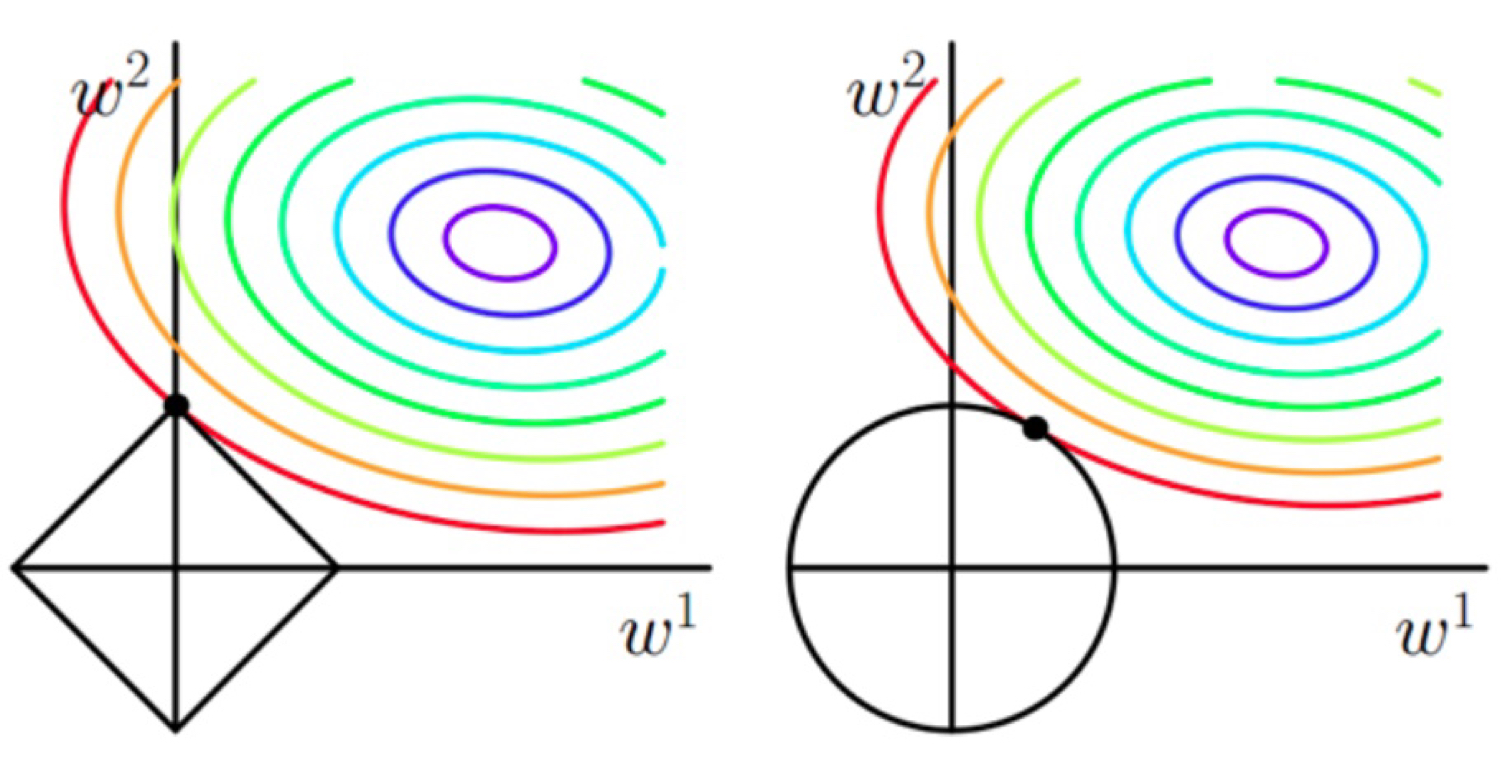
正在回答 回答被采纳积分+3
1回答
相似问题
KNN模型也有模型正则化的操作吗?
1551
1
3


“在逻辑回归中使用正则化”
1111
0
4


njobs的问题
1802
0
2


模型正则化好像只适用于回归问题?
960
0
2
老师一般面试中会问正则相关的题目吗?
966
1
1


登录后可查看更多问答,登录/注册








