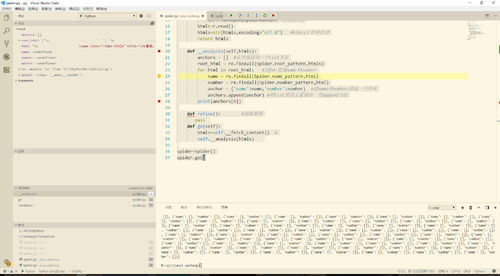
为什么这里的name和number传不进去
import re
from urllib import request
class Spider():
url = 'https://www.panda.tv/cate/lol'
root_pattern = '<div class="video-info">([\s\S]*?)</div>'
name_pattern = '</i>([\s\S*?])</span>'
number_pattern ='<span class="video-number">([\s\S*?])</span>'
def __fetch_content(self):
r=request.urlopen(Spider.url) #爬取页面
htmls=r.read()
htmls=str(htmls,encoding="utf-8") #htmls字符串转译
return htmls
def __analysis(self,htmls):
anchors = [] #在外面添加一个list方法
root_html = re.findall(Spider.root_pattern,htmls)
for html in root_html: #用for查找name和number
name = re.findall(Spider.name_pattern,html)
number = re.findall(Spider.number_pattern,html)
anchor = {'name':name,'number':number} #把name和number拼成一个字典
anchors.append(anchor) #将list里的元素添加 用append方法
print(anchors[0])
def refine(): #精炼数据
pass
def go(self):
htmls=self.__fetch_content() #
self.__analysis(htmls)
spider=Spider()
spider.go()
正在回答
2回答


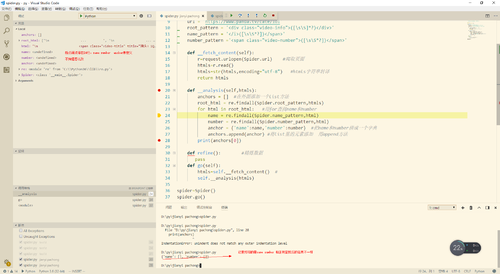 在图上做了标注
在图上做了标注相似问题





登录后可查看更多问答,登录/注册











