正在回答 回答被采纳积分+3
1回答
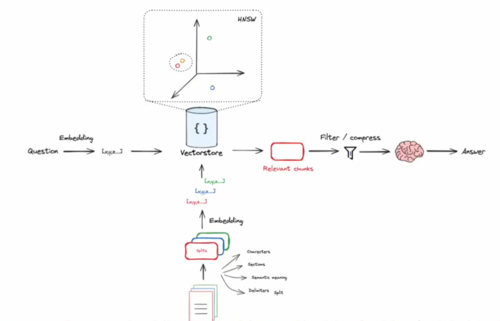
相似问题
切割和向量化有什么关系?切割的规则如何设定?
682
0
5


为什么求单位向量以及负的标准向量是做什么的?
2081
1
3




如何把数据库的数据同步到向量数据库
1604
1
3
前面的提到的Qdrant向量数据库与Memory有什么区别
816
0
3
登录后可查看更多问答,登录/注册




