关于filter
请问这条代码有问题吗,我是3.7的python,打断点看前面可以提取出https开头的url,但是到这里过滤一下就为none了。
# all_urls = filter(lambda x: True if x.startswith("https") else False, all_urls)
1217
收起
正在回答
3回答
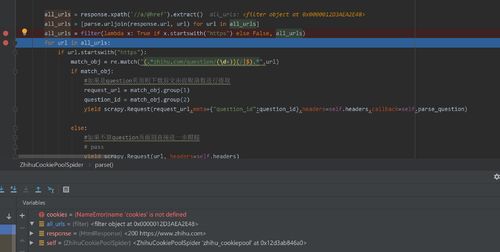
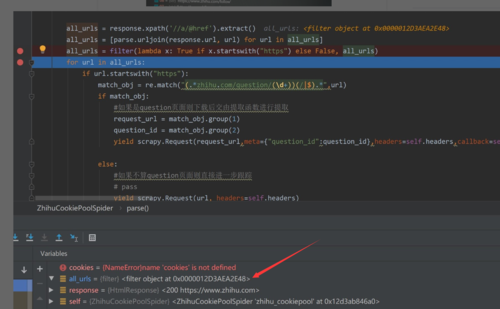 你这里看起来对象不是none啊
你这里看起来对象不是none啊
相似问题
关于权限拦截的问题
1340
0
3


关于列表解析和filter()性能问题
1425
1
3




filter 条件关于外键 的疑问
1422
2
3


filter和filter-mapper这两个,哪个在前?
867
0
2


ionic3有没有filter过虑器呀?
740
0
3


登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











