关于交叉验证随机性
老师好,请问下 交叉验证分成K份,是有什么规则吗?
以下图为例,训练数据分成了3份 (A、B、C),请问是根据什么规则分成3份的?
比如我有99条数据,分成3份,是否
A = 第1-33条数据
B = 第34-66条数据
C = 第67-99条数据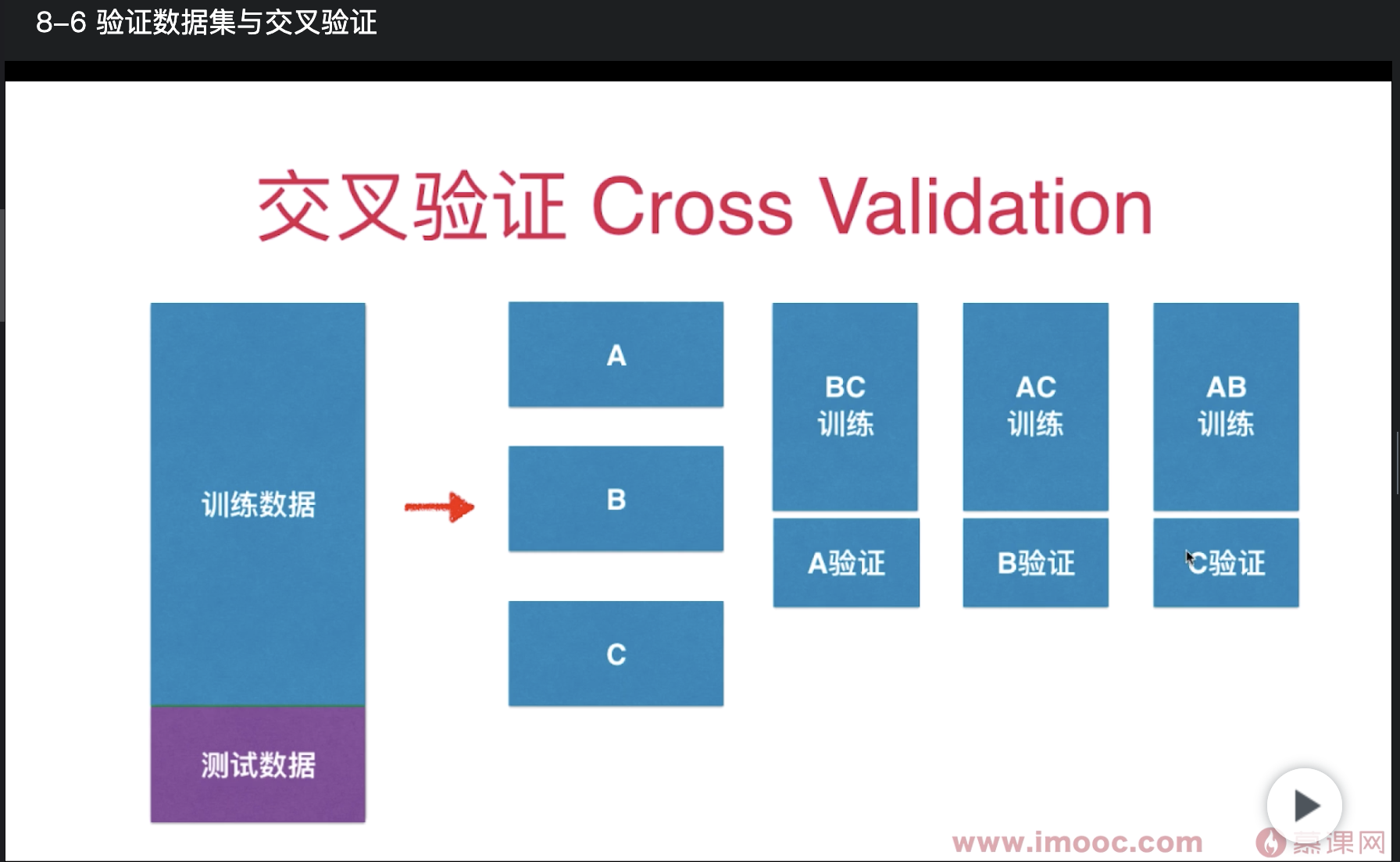
627
收起
正在回答 回答被采纳积分+3
1回答
相似问题
关于分割数据集的随机问题
2015
2
5


交叉验证真的科学吗?
1566
9
4
交叉验证训练的模型用哪个呢?
2631
2
9
为什么要用交叉验证?
2012
0
5
交叉验证的疑惑
1849
2
3
登录后可查看更多问答,登录/注册








