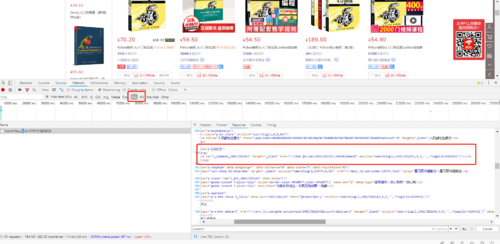
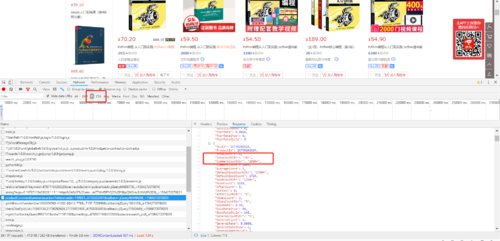
京东网a标签只能读取其属性,不能读取其文本内容
京东网爬取不到 评论数量
我已经确定找到了 评论数量的那个 a标签对象, 也能读取 那个a标签的属性,比如 评论地址,,但就是不能读取 a标签对象的 文本,是不是跟 编码 有关系?? 但其它a标签文本都能读取啊,想不明白。
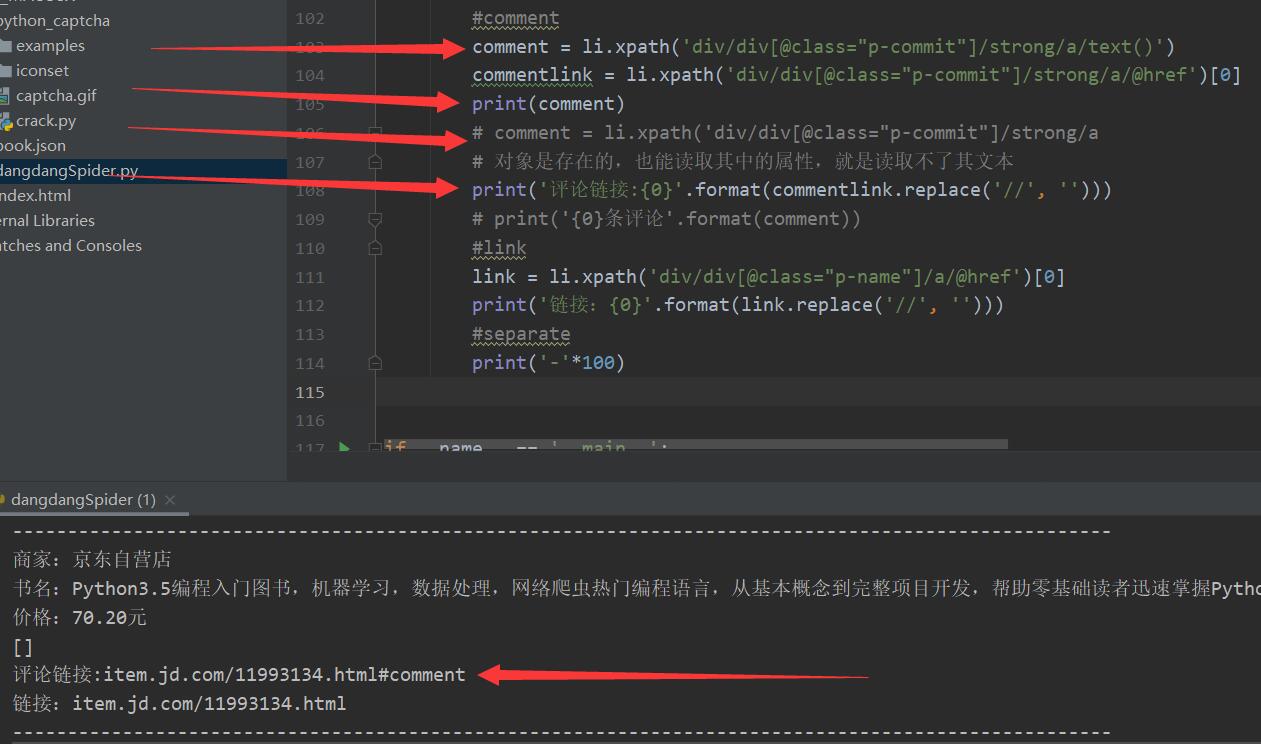

1188
收起
京东网爬取不到 评论数量
我已经确定找到了 评论数量的那个 a标签对象, 也能读取 那个a标签的属性,比如 评论地址,,但就是不能读取 a标签对象的 文本,是不是跟 编码 有关系?? 但其它a标签文本都能读取啊,想不明白。