name取为空
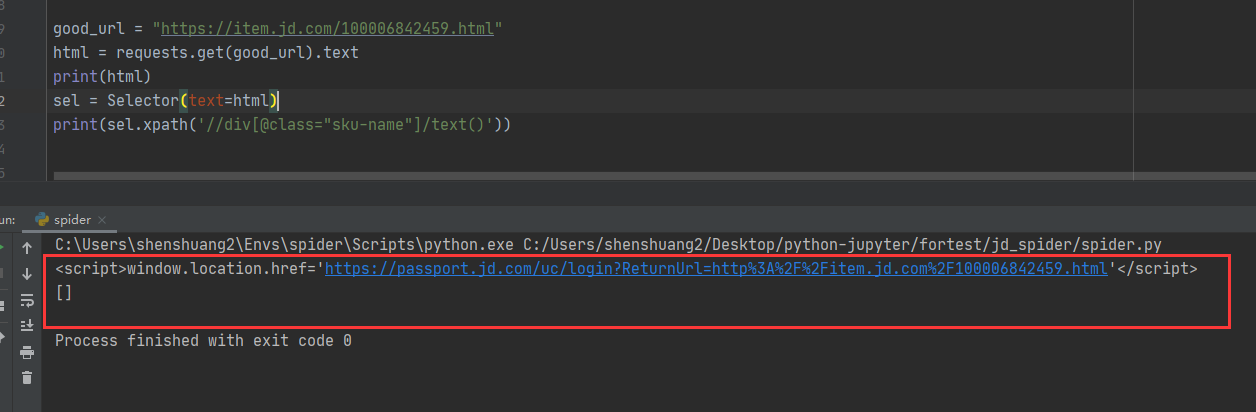
name昨天还是能取到值的,今天再运行就一直取的都是空值,打印出来的html链接点进去是京东登录的界面,是不是因为这个原因啊?老师有没有什么反爬的方法吗?
1085
收起
正在回答
2回答

相似问题






登录后可查看更多问答,登录/注册
name昨天还是能取到值的,今天再运行就一直取的都是空值,打印出来的html链接点进去是京东登录的界面,是不是因为这个原因啊?老师有没有什么反爬的方法吗?
登录后可查看更多问答,登录/注册





