关于对随机种子对KNN分类器准确率的影响
老师您好,在写论文的时候用KNN算法,结论里需要给出一个预测的准确率。但其实在数据归一化、超参数网格搜索都完成之前,train_test_split时的随机种子对最后的准确率也是有影响的。
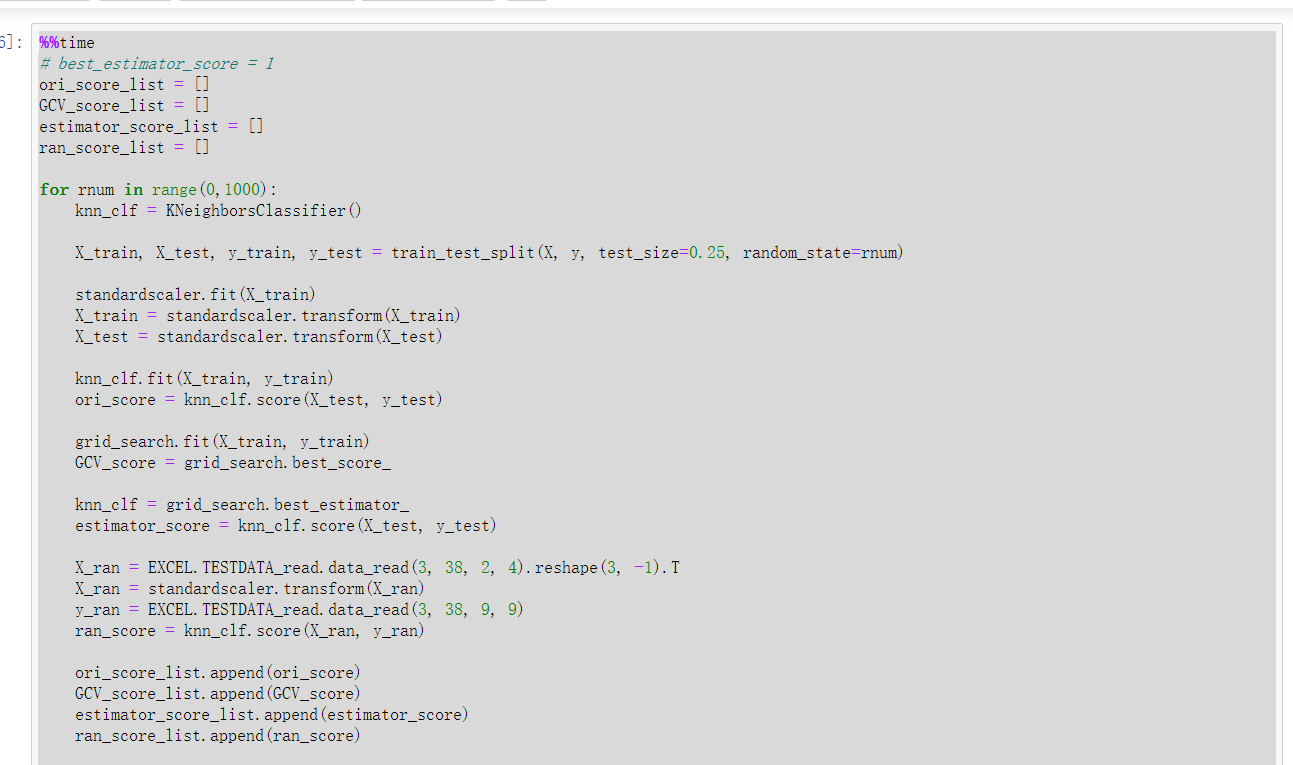
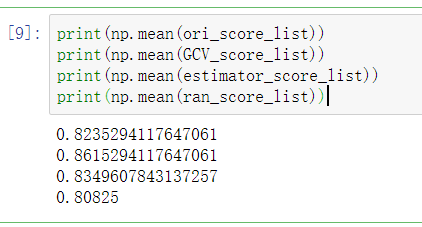
我编写程序,在完成数据归一化和超参数的网格搜索之外,对随机种子进行了从0到999的搜索,发现当随机种子取799时,预测准确率最低为,62.7%,当随机种子取910时,预测准确率最高,为96.1%。
那这个时候到底该怎么评价这个KNN分类器的准确度?
我尝试取1000个随机种子准确率的平均值:83.5%,但是此准确率是没有对应的K值和p值的,因为随机种子不同,网格搜索得到的最佳K值和p值也不同。
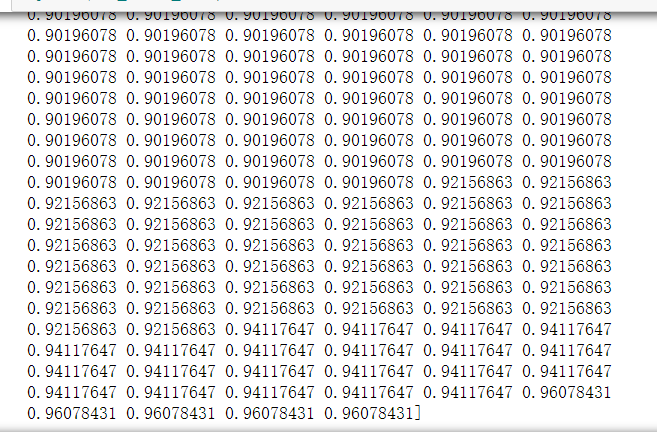
另外我对您讲课时用的鸢尾花数据集也在0到99间对随机种子进行了搜索,发现最高100%,最低86.8%,对应的随机种子分别是63和74。相差还是挺大的。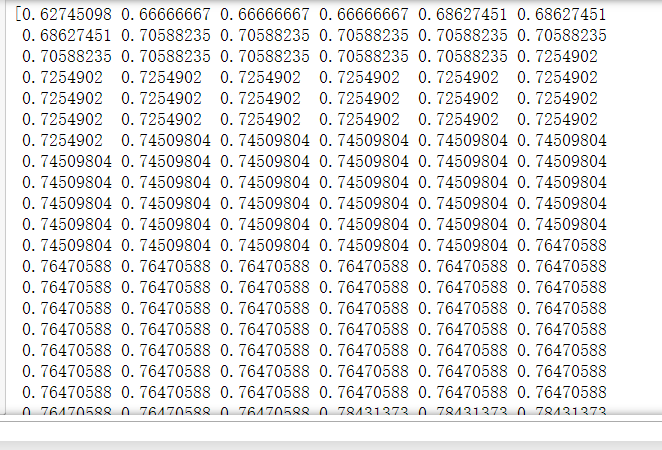
2400
收起
正在回答 回答被采纳积分+3
1回答
相似问题
KNN归一化后准确率反而下降
3844
1
6


多分类如何根据混淆矩阵求准确率、精准率、和召回率?
8194
1
14
导出码率和分辨率影响的区别?
1177
0
3


train_test_split设定随机种子对score的影响
1224
0
2
平衡数据集对构建模型的影响
1736
0
3


登录后可查看更多问答,登录/注册








