Scrapy+Redis实现增量爬取,不执行callback函数(Debug模式打断点会执行)
老师,如题。
按照之前请教过您的方案,尝试通过Redis的 pub/sub实现增量爬虫,执行时,发现yield Request()后没执行正常去callback函数。
但是在debug模式下打来断点,就能正常进入,请老师帮忙分析下
代码如下: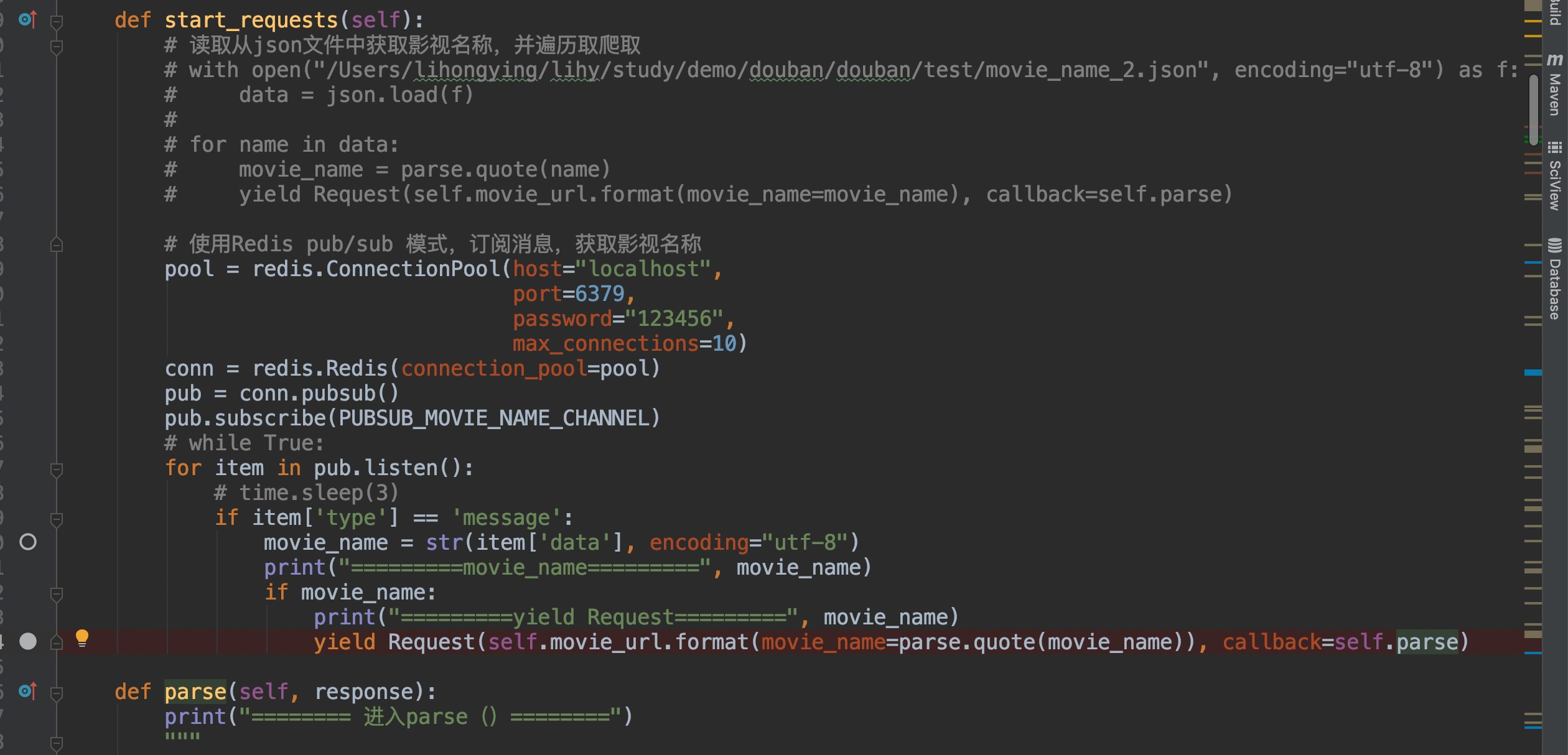
日志如下: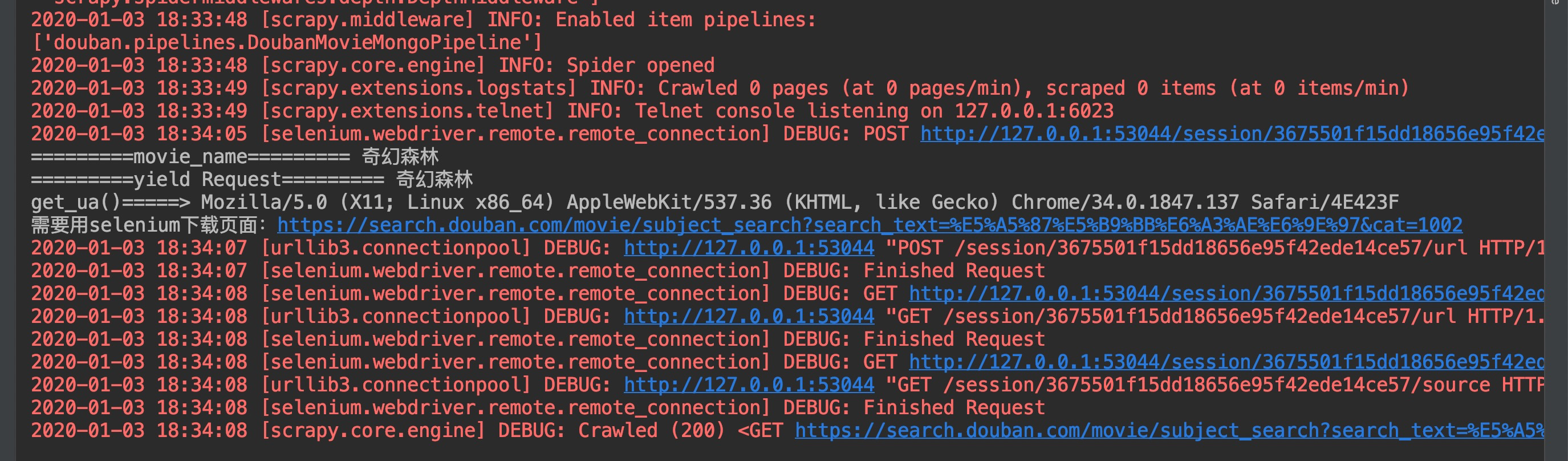
日志在如截图的那里,感觉就卡住了,正常解析的话,还有很多日志的。
PS: 尝试在for循环中sleep,也没用
1509
收起
正在回答 回答被采纳积分+3
1回答
相似问题
scrapy-redis怎么做增量爬取
1863
0
5


ReactNative debug模式下 不能进行打断点?
3054
0
4


老师,用scrapy-redis怎么实现深度优先啊
1402
0
5





scrapyd部署scrapy后无法关闭爬虫
1987
0
1
登录后可查看更多问答,登录/注册
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











