选择排序性能分析疑问
老师,我在分析选择排序对随机数组和近乎有序数组排序的性能差异时,我认为在数组长度一致的条件下,选择排序对近乎有序的数组排序时间应该更短,原因是在查找 [i,数组长度)这个区间内的最小值的时候,找到的最小值,多数时候还是i本身,就不用进行交换了, 但是在实际测试的时候,发现两种情况下,选择排序的用时差别不大,甚至对近乎有序数组的排序时间更长一点,希望老师有时间的时候看看我的分析对不对。
以下是js版本代码的测试结果,其余排序的结果是正常的,只有选择排序不在我的预料内。
麻烦老师了,感谢!!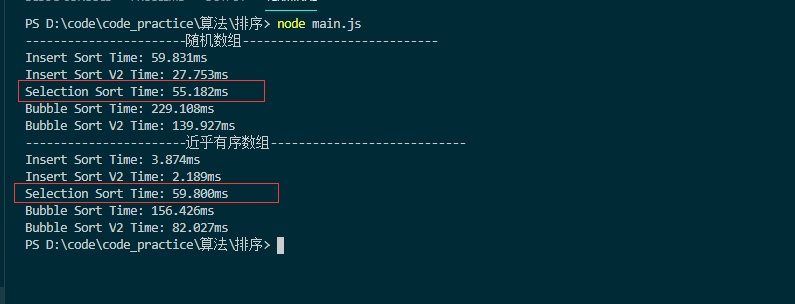
956
收起
正在回答
1回答

相似问题
选择排序 这样做 是不是更好
1385
0
8




关于mybaties排序问题
1027
0
5




选择排序疑问
951
0
2
插入排序
1402
0
4


老师我不明白希尔排序为什么能那么快
1742
5
3
登录后可查看更多问答,登录/注册








