Scrapy-Redis爬虫启动后,是如何做到进程不Close的
老师,直接使用Scrapy的话,在爬虫执行结束后,会被close, 最后的日志基本像这样:
2020-01-15 11:36:51 [scrapy.core.engine] INFO: Spider closed
(finished)
那么,scrapy-redis 是在哪里实现,当没有爬取任务的时候,进程不被关闭的呢?
另外,关于scrapy-redis, 还有几个疑问,顺便请教下老师
1、如果不需要去修改源代码进行扩展,是不是可以通过:pip install scrapy-redis 安装就行,而不需要将源码集成到项目中啊? (这个我看文档是支持直接 install 和下载源码 2种方式的)
2、当往队列发布start_urls的消息后, scrapy是如何实时监听到消息的(中间可能没有执行任务,当往队列push url, 能实时监听到),这个我在源码中一直没找到
1294
收起
正在回答 回答被采纳积分+3
2回答

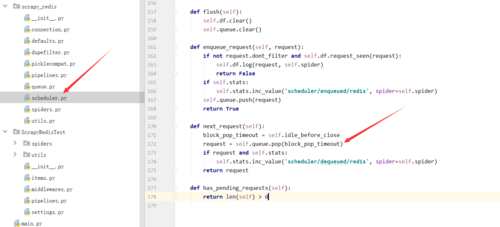 ,每次获取下一个url都是这行代码完成的,你只要搞清楚这里的queue是怎么初始化的以及获取的时候是从哪里获取的就知道怎么办了
,每次获取下一个url都是这行代码完成的,你只要搞清楚这里的queue是怎么初始化的以及获取的时候是从哪里获取的就知道怎么办了
Scrapy打造搜索引擎 畅销4年的Python分布式爬虫课
- 参与学习 5831 人
- 解答问题 6293 个
带你彻底掌握Scrapy,用Django+Elasticsearch搭建搜索引擎
了解课程











