如何添加主键
PK哥,请问怎样为写出去的一张表指定主键id呢。
从网上搜索到的解决方案是:
val filterDS: Dataset[Row] = jdbcDF.select("name", "image").filter( $"name" === "华为" || $"name" === "小米")
// 在原Schema信息的基础上添加一列“id”信息
val schema: StructType = filterDS.schema.add(StructField("id", LongType))
// DataFrame转RDD, 然后调用 zipWithIndex
val dfRDD: RDD[(Row, Long)] = filterDS.rdd.zipWithIndex()
// 将id字段合并在一起,merge顺序不可修改,因为添加id的schema字段在最后一个
val rowRDD: RDD[Row] = dfRDD.map(tp => Row.merge(tp._1, Row(tp._2)))
// 将添加了索引的RDD转化为 DataFrame
val result: DataFrame = spark.createDataFrame(rowRDD, schema)
执行后写入数据库的结果表,发现id列并没有加上主键约束,只是单纯的一个值。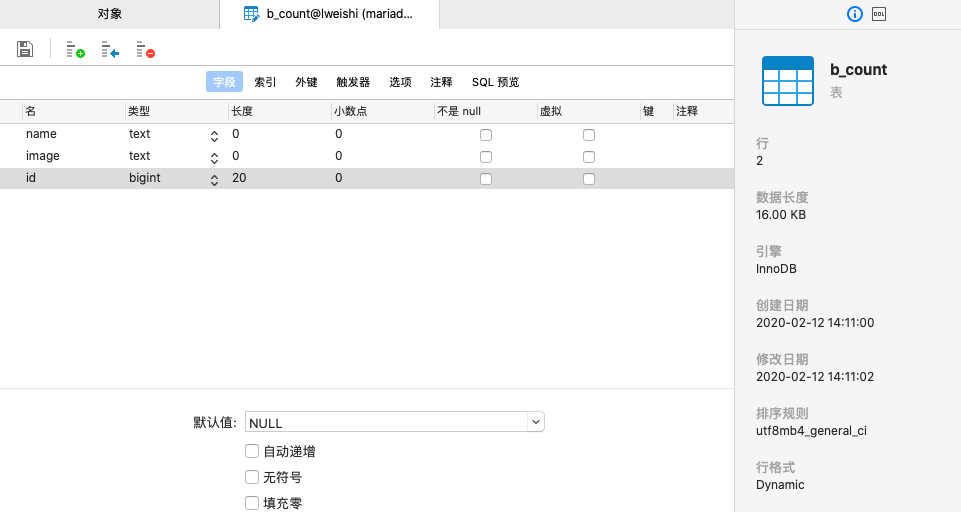
请问PK哥,该如何加上约束呢?
1210
收起
正在回答
2回答

相似问题
我在pcx集群里添加数据,主键自增id不是连续的是为什么
1769
0
5


关于mysql主键ID默认值的问题
1032
0
2


如何自动添加编写人?
987
0
2


请教一下如何自动设置域名
1088
0
4
添加了主键之后无法添加数据到数据库
1257
0
5
登录后可查看更多问答,登录/注册









