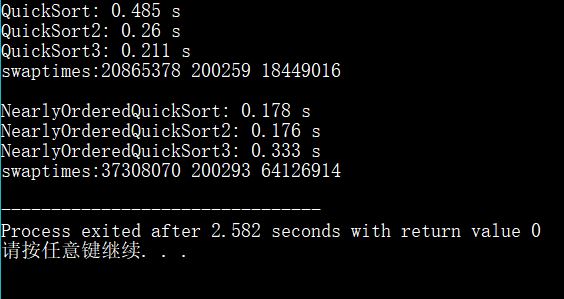
为什么我的三路快排在无序数组排序的时候性能好于两路快排?
#include
#include
#include
#include"SortTestHelper.h"
#include"MergeSort.h"
#include"InsertionSort.h"
using namespace std;
int count1=0,count2=0,count3=0; //比较一下交换次数
template //已经改为随机快排
int Partition(T arr[],int l,int r) {
swap(arr[l],arr[rand()%(r-l+1)+l]); //随机交换头和其中一个元素
T aux=arr[l];
int i,j=l;
for(i=l+1; i<=r; i++) {
if(arr[i]<aux) {
j++;
swap(arr[j],arr[i]);
count1++;
}
}
swap(arr[l],arr[j]);
count1++;
return j;
}
template
int Partition2(T arr[],int l,int r) {
swap(arr[l],arr[rand()%(r-l+1)+l]); //随机交换头和其中一个元素
T aux=arr[l];
int i=l+1,j=r,lt,gt;
while(true){
while(i<=r&&arr[i]<aux) i++; //为什么不能是等于呢?
while(j>=l+1&&arr[j]>aux) j–; //为什么不能是等于呢?
if(i>j){
break;
}
swap(arr[i],arr[j]);
count2++;
i++;
j--;
}
swap(arr[l],arr[j]);
count2++;
return j;
}
template
void __QuickSort(T arr[],int l,int r) {
if(r-l<=15) {
BetterInsertionSort(arr,l,r);
return; //判断递归终止的条件
}
int p=Partition(arr,l,r);
__QuickSort(arr,l,p-1);
__QuickSort(arr,p+1,r);
}
template //两路快排
void __QuickSort2(T arr[],int l,int r) {
if(r-l<=15) {
BetterInsertionSort(arr,l,r);
return; //判断递归终止的条件
}
int p=Partition2(arr,l,r);
__QuickSort(arr,l,p-1);
__QuickSort(arr,p+1,r);
}
template //三路快排
void __QuickSort3(T arr[],int l,int r) {
if(r-l<=15) {
BetterInsertionSort(arr,l,r);
return; //判断递归终止的条件
}
swap(arr[l],arr[rand()%(r-l+1)+l]);
int i=l+1,j=r,lt=l,gt=r+1; //注意每一个变量的定义
T aux=arr[l];
while(i<gt){
if(arr[i]<aux){
swap(arr[lt+1],arr[i]);
count3++;
lt++;
i++;
}else if(arr[i]>aux){
swap(arr[i],arr[gt-1]);
count3++;
gt–;
}else{
i++;
}
}
swap(arr[l],arr[lt]);
count3++;
__QuickSort3(arr,l,lt-1);
__QuickSort3(arr,gt,r);
}
template //由普通的基本快排优化到随机快排
void QuickSort(T arr[],int n) {
srand(time(NULL));
__QuickSort(arr,0,n-1);
}
template //随机的两路快排
void QuickSort2(T arr[],int n) {
srand(time(NULL));
__QuickSort2(arr,0,n-1);
}
template //随机的三路快排
void QuickSort3(T arr[],int n) {
srand(time(NULL));
__QuickSort3(arr,0,n-1);
}
int main() {
int n=1000000;
int *arr2=SortTestHelper::generateNearlyOrderedArray(n,100);
int *arr4=SortTestHelper::copyArray(arr2,n);
int *arr6=SortTestHelper::copyArray(arr2,n);
int *arr=SortTestHelper::generateArray(n,0,n);
int *arr1=SortTestHelper::copyArray(arr,n);
int *arr3=SortTestHelper::copyArray(arr,n);
SortTestHelper::testSort("QuickSort",QuickSort,arr,n);
SortTestHelper::testSort("QuickSort2",QuickSort2,arr1,n);
SortTestHelper::testSort("QuickSort3",QuickSort3,arr3,n);
cout<<"swaptimes:"<<count1<<" "<<count2<<" "<<count3<<endl;
cout<<endl;
SortTestHelper::testSort("NearlyOrderedQuickSort",QuickSort,arr2,n);
SortTestHelper::testSort("NearlyOrderedQuickSort2",QuickSort2,arr4,n);
SortTestHelper::testSort("NearlyOrderedQuickSort3",QuickSort3,arr6,n);
cout<<"swaptimes:"<<count1<<" "<<count2<<" "<<count3<<endl;
delete[] arr;
delete[] arr1;
delete[] arr2;
delete[] arr3;
delete[] arr4;
delete[] arr6;
return 0;
}
正在回答
1回答
相似问题


登录后可查看更多问答,登录/注册








