Redis课后讨论
一哥你好。
1、首先我想说说我对Key命名的理解。第一次接触到redis是在某教学视频中,一般都是这种形式。
redisTemplate.opsForValue().set("user_" + id,new Object());
Object o = redisTemplate.opsForValue().get("user_" + id);
相信大多数人一开始接触redis都是这种代码,甚至直接以id为key。说实话,一开始我对这种key的使用方式也是觉得没啥问题。直到有一次我写了类似下面这段代码。
Object o = redisTemplate.opsForValue().get("user" + id);//key少了一个下划线
后果就是虽然有对取出的user进行判空可以将错就错,但是这样的缓存是无法保证一致性的(做一致性处理的只有"user_")。也就是一开始不会有什么问题,无非就是往redis中多加了个缓存而已,可一旦出现一致性的问题而且是在生产环境上,那么面对的就是客户铺天盖地的投诉了。
那么如何避免这个问题?我一开始的想法很简单,复制粘贴就好了,使用已有缓存必须复制之前的key规则,遵照这个规范基本不会犯错(因为后端接口只有我自己一个人开发)。闲下来的时候我也会想,这种如此主观的处理真的合适么?说到底这还是项目中存在魔法值的问题,能对抗魔法值的是什么?枚举!由于之前就想着要写一套redis使用的工具类,但是传统方法用着也不是特别难受就一直搁置着。可是这次的思路一出现,我就立马着手去实现这个方案。
首先是key的命名,当然是运用枚举去列举所有需要的key,加上为了在RDM上更好的观察数据,对命名上也进行了分包(运用redis的冒号分隔符来分组)。最后实现出来的样子如下:
@Getter
@AllArgsConstructor
public enum RedisKeyEnum {
USER("user", "userId_"),//用户缓存,以用户Id为key
ROLE("role", "roleId_");//角色缓存,以角色Id为key
private String folder;//分类名
private String keyPrefix;//key前缀(对key的描述) 必填项
}
再来是redis的工具类,基本是从博客上抄下来的,然后进行改动(主要是针对key的构造)。
public <T> T get(RedisKeyEnum keyEnum, String key, Function<String,T> function) {//篇幅原因,省略实现
public void set(RedisKeyEnum keyEnum, String key, Object value);
public void delete(RedisKeyEnum keyEnum, String key);
在此之上,我又模仿了HashMap的computeIfAbsent方法,对get进行了优化。以下是传统写法:
User u = (User) redisTemplate.opsForValue().get("user_" + id);
if(u == null){
//从数据库获取或其他
}
接下来是改良后
User u= redisUtil.get(RedisKeyEnum.USER, "100", s -> new User());
对key的改造中隐藏了对key繁琐且容易出现失误的拼接,采用了指定缓存枚举+id为入参。只要枚举中的注释能够写明白,那么在多人开发的背景下对缓存的复用也提供了便利。最后附上一张rdm中的效果: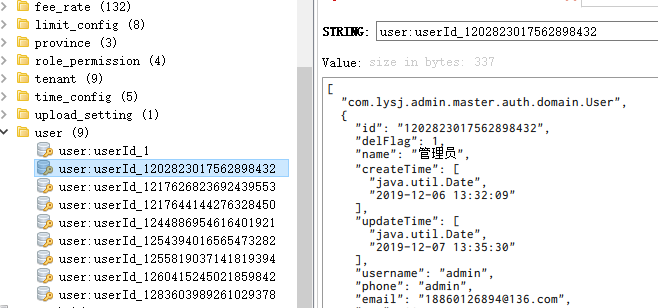
2、用过哪些数据类型?
说来有点惭愧,目前只用过K-V类型,V采用json字符串。以前也有想过是否要用下其他数据类型,但K-V用起来确实太酸爽了,就算有一些特殊需求如去重或者排序,也可以加载到代码中进行处理。我也秉承自己目前信奉的开发规则,若无必要,勿增实体。
不过还是想问下一哥,梭哈K-V是否有弊端?我目前的猜想是数据从redis加载,在代码中处理,再set回redis中,此过程非原子性操作,会有脏数据风险。而且大量数据的json转换也会损耗性能。当然这只是我的猜想,接触的项目中也没有这么庞大的规模让我发现错误
正在回答
1回答

相似问题







登录后可查看更多问答,登录/注册







