关于Bellman-Ford算法我的实现
老师, 不好意思, 由于我是Java实现的, 你的ppt将的我有点听懂了,但是又有点没听懂, 后来自己看了好多博客, 还是有点懵懂的感觉, 下面我讲我的思路分享一下, 经过确定是可以获取到最短路径和判断是否存在负权边的, 测试用例用的是老师提供的测试用例
思路:
需要的数据结构:
<1> int[] from: 代表了每一个顶点的最短路径是从哪个顶点来的
<2> double[] weight: 代表了从原点0到其它顶点最短路径的权重
<3> boolean hasNegativeCycle: 是否存在负权环
<4> Graph<T> graph: 图的引用
<5> LinkedList<Integer> queue: 利用Java中LinkedList来实现队列的操作
实现过程:(类似于层次遍历)
首先初始化from[0], 以及weight[0]为0, 初始化其它顶点的权重为99999999,
初始化hasNegativeCycle为false(即一开始认为没有负权边), 将原点0压入队列
然后, 从队列中取出一个顶点a, 对该顶点的相邻边进行遍历, 一旦当前边的权重 + a的权
重 < a原来的权重, 那么就认为这次的松弛操作是成功的, 然后将该相邻边的另一个顶点
压入队列, 这样以后, 等于对每一个条边都进行了一次遍历, 由这些边的权重来不停的更换
这些边对应顶点的最短路径
关于处理负权环:(这个说的比较乱, 老师可以直接看代码)
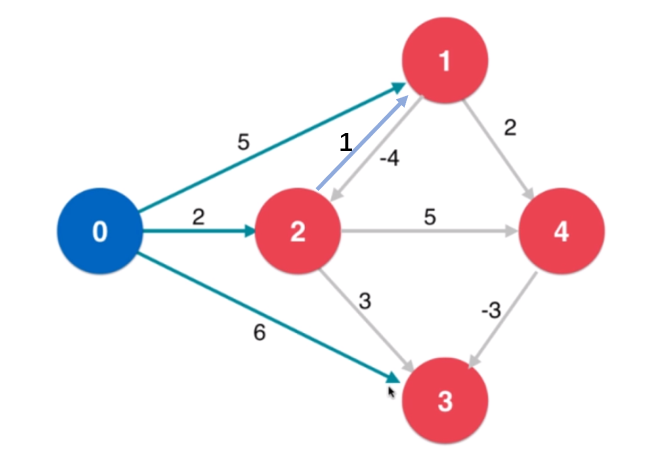
由上图可得, 顶点1, 顶点2 是会形成负权环的, 那么在对顶点0遍历的过程中, 我会把1,
2, 3顶点压入队列, 同时更新1, 2, 3顶点最短路径权值, 然后对顶点1进行遍历, 对顶点1
进行遍历的时候,发现由顶点1到顶点2会形成一个更小的最短路径, 由此更新顶点2的最短路
径权重, 遍历完成后会将顶点1的相邻顶点压入队列, 接下来对顶点2进行遍历, 发现由顶点
2到顶点1会形成更小的最短路径, 从而更新顶点1的最短路径, 再将顶点1压入队列,从而形
成死循环, 所以我的处理是当遍历相邻顶点的时候, 如果发现这个相邻顶点跟当前顶点的最
短路径的来源顶点相同时, 说明会进入死循环, 同时也证明了存在负权环, 所以此时将
hasNegativeCycle设置为true, 并return, 此时没必要再进行最短路径的判断了
package bellmanford;
import java.util.ArrayList;
import java.util.LinkedList;
import weightgraph.Edge;
import weightgraph.Graph;
import weightgraph.Iterators;
public class BellmanFord<T extends Comparable<T>> {
private Graph<T> graph; // 图的引用
private int[] from; // 顶点的来向
private double[] weight; // 各个顶点到原点的最短路径
private boolean hasNegativeCycle; // 是否存在负权环
public BellmanFord (Graph<T> graph) {
this.graph = graph;
this.from = new int[graph.getPeak()];
this.weight = new double[graph.getPeak()];
// 初始化所有的顶点的来源为-1, 以及所有顶点的权重为无穷大
for (int i = 0; i < graph.getPeak(); i++) {
from[i] = -1;
weight[i] = 999999999;
}
hasNegativeCycle = false;
generateShortestPath();
}
/**生成从原点到任意一点的单源最短路径**/
public void generateShortestPath () {
// 初始化顶点0
from[0] = 0;
weight[0] = 0;
LinkedList<Integer> queue = new LinkedList<>();
queue.addLast(0);
while (!queue.isEmpty()) {
int index = queue.removeFirst();
Iterators iterator = graph.iterator(index);
while (!iterator.end()) {
Edge<T> edge = (Edge<T>)iterator.next();
int toPeak = edge.getToPeak();
double w = (Double)edge.getWeight();
// 出现负权环的情况
if (toPeak == from[edge.getFromPeak()]) {
hasNegativeCycle = true;
return;
}
// 如果当前顶点的权值加上上一层的权值小于weight种当前顶点的权值, 就进行替换
if (w + weight[index] < weight[toPeak]) {
weight[toPeak] = w + weight[index];
from[toPeak] = index;
}
queue.addLast(toPeak);
}
}
}
// 获取指定顶点的最短路径权重
public double getWeight (int i) {
if (hasNegativeCycle) {
throw new IllegalArgumentException("the weighted graph has nagatived cycle!");
}
return weight[i];
}
// 获取指定顶点的最短路径
public String showShortestPath (int i) {
if (hasNegativeCycle) {
throw new IllegalArgumentException("the weighted graph has nagatived cycle!");
}
ArrayList<Integer> path = new ArrayList<Integer>();
while (from[i] != i) {
path.add(i);
i = from[i];
}
path.add(0);
StringBuilder str = new StringBuilder();
for (int j = path.size() - 1; j >= 0; j --) {
str.append(path.get(j));
if (j >= 1) {
str.append(" -> ");
}
}
return str.toString();
}
}
下面是Graph和Edge的实现(跟老师的差不多)
package weightgraph;
import java.util.ArrayList;
public class SparseWeightedGraph<T extends Comparable<T>> implements Graph<T> {
private int peak;
private int edge;
private boolean directed;
private ArrayList<Edge<T>>[] graph;
@SuppressWarnings("unchecked")
public SparseWeightedGraph (int peak, boolean directed) {
this.peak = peak;
this.directed = directed;
this.graph = (ArrayList<Edge<T>>[])new ArrayList[peak];
for (int i = 0; i < peak; i++) {
graph[i] = new ArrayList<Edge<T>>();
}
}
@Override
public void addEdge(int a, int b, T width) {
assert a >= 0 && b >= 0 && a < peak && b < peak;
// 没有考虑如果a->b已经存在的情况, 因为在稀疏图中判断是否存在一条边需要遍历当前顶点的对应顶点
graph[a].add(new Edge<T>(a, b, width));
if (!directed) {
graph[b].add(new Edge<T>(b, a, width));
}
edge++;
}
@Override
public boolean hasEdge(int a, int b) {
return graph[a].get(b) != null;
}
@Override
public int getPeak() {
return peak;
}
@Override
public int getEdge() {
return edge;
}
@Override
public Iterators iterator(int a) {
return new Iterator(a);
}
private class Iterator implements Iterators {
private int a; // 迭代的顶点
private int curIndex; // 当前正在被迭代的边
public Iterator (int a) {
this.a = a;
curIndex = 0;
}
@Override
public Edge<T> next() {
if (curIndex >= graph[a].size()) {
return null;
}
return graph[a].get(curIndex++);
}
@Override
public boolean end() {
return curIndex >= graph[a].size() ;
}
}
}
package weightgraph;
public class Edge<T extends Comparable<T>> implements Comparable<Edge<T>>{
// 对于from, to来说, 只有在有向图的时候其意义才会不同
private int from; // 表示边的第一端
private int to; // 表示边的第二端
private T weight; // 边的权重, 用泛型表示, 因为可以是整型, 可以是浮点型
public Edge (int from, int to, T weight) {
this.from = from;
this.to = to;
this.weight = weight;
}
public void setWeight (T weight) {
this.weight = weight;
}
public T getWeight () {
return weight;
}
public int getToPeak () {
return to;
}
public int getFromPeak () {
return from;
}
@Override
public String toString () {
return "{from: "+ from + ", to: "+ to + ", weight: " + weight +"}";
}
@Override
public int compareTo(Edge<T> o) {
if (o == null) {
throw new IllegalArgumentException("Edge of o does not exist");
}
return weight.compareTo(o.weight);
}
}
1693
收起
正在回答 回答被采纳积分+3
1回答
相似问题
关于Bellman-Ford的过程
2063
4
8


关于9.4节中Bellman-Ford的算法
3219
9
9


bellman-ford
1098
0
1
关于Bellman-Ford中第一轮松弛操作后dis[]数组的理解问题
2222
6
9




关于9-4节Bellman Ford算法两个问题
1273
1
4


登录后可查看更多问答,登录/注册








