逻辑回归二分类问题
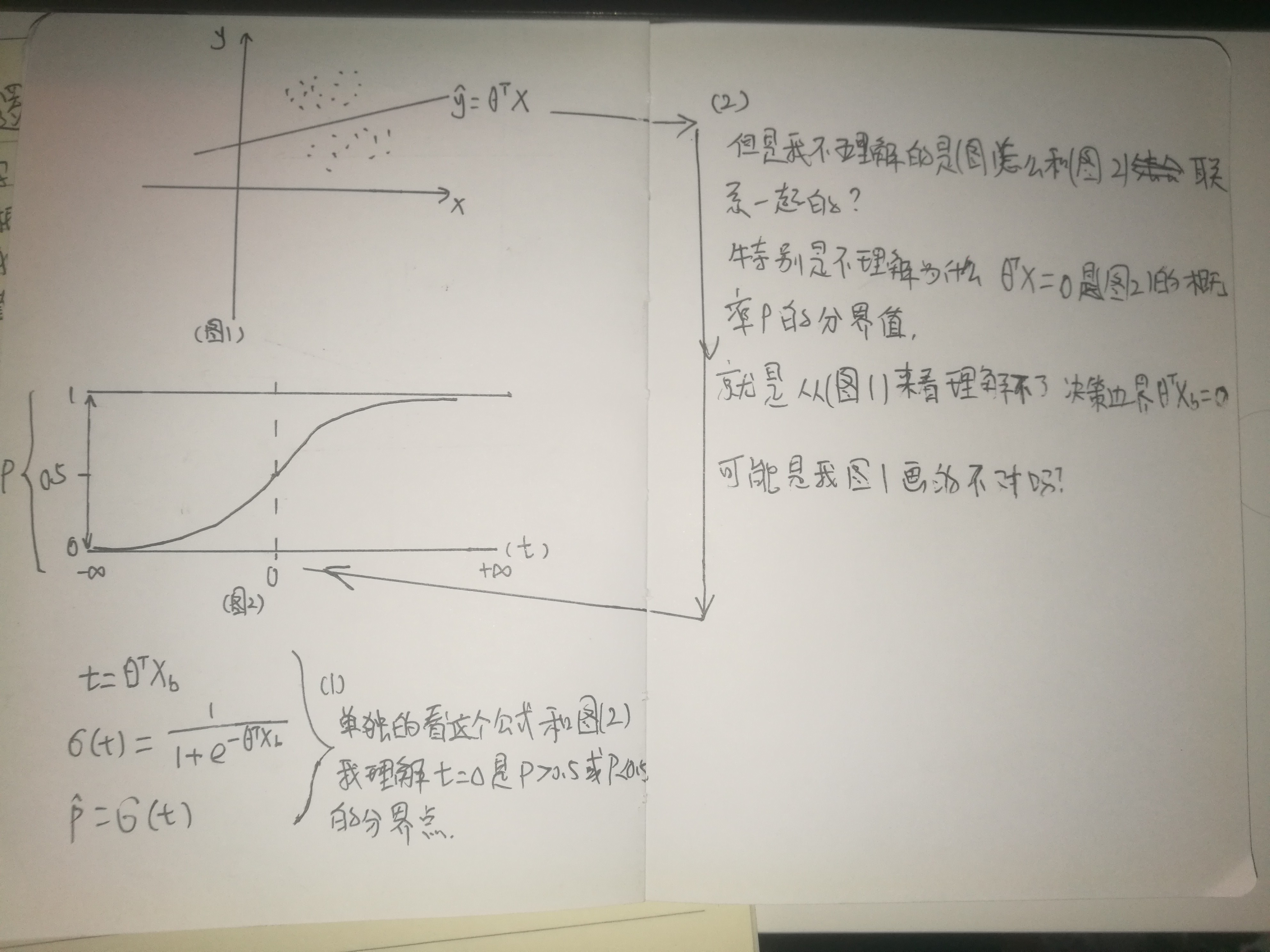
老师,帮我纠正一下思路,我不太理解图片上的问题,不知道为什么图1中的y’=Θx=0时是图2中的t=0对应概率p的分界点。不知道他们两者是怎么联系一起的,是不是因为图1我画的不对进而理解错了。我把值y’=Θx理解成一个样本的值了,但是样本值的y肯定是没有所谓的等于0的特殊性意义的。
1740
收起
正在回答
2回答

相似问题
问下逻辑回归中的“逻辑”是什么意思,为什么叫逻辑,是怎么来的?
3456
1
4


多元线性回归和softmax回归问题
1692
1
4
关于逻辑回归能解决几个分类的问题
602
0
2


逻辑回归算法小问题
1004
0
1


波波老师,逻辑回归可以解决回归问题吗
2679
1
2
登录后可查看更多问答,登录/注册








