老师,这个random_state 起到了什么作用?
我在使用scikit-learn中,如果不加上random_state,出来的图形是这样的。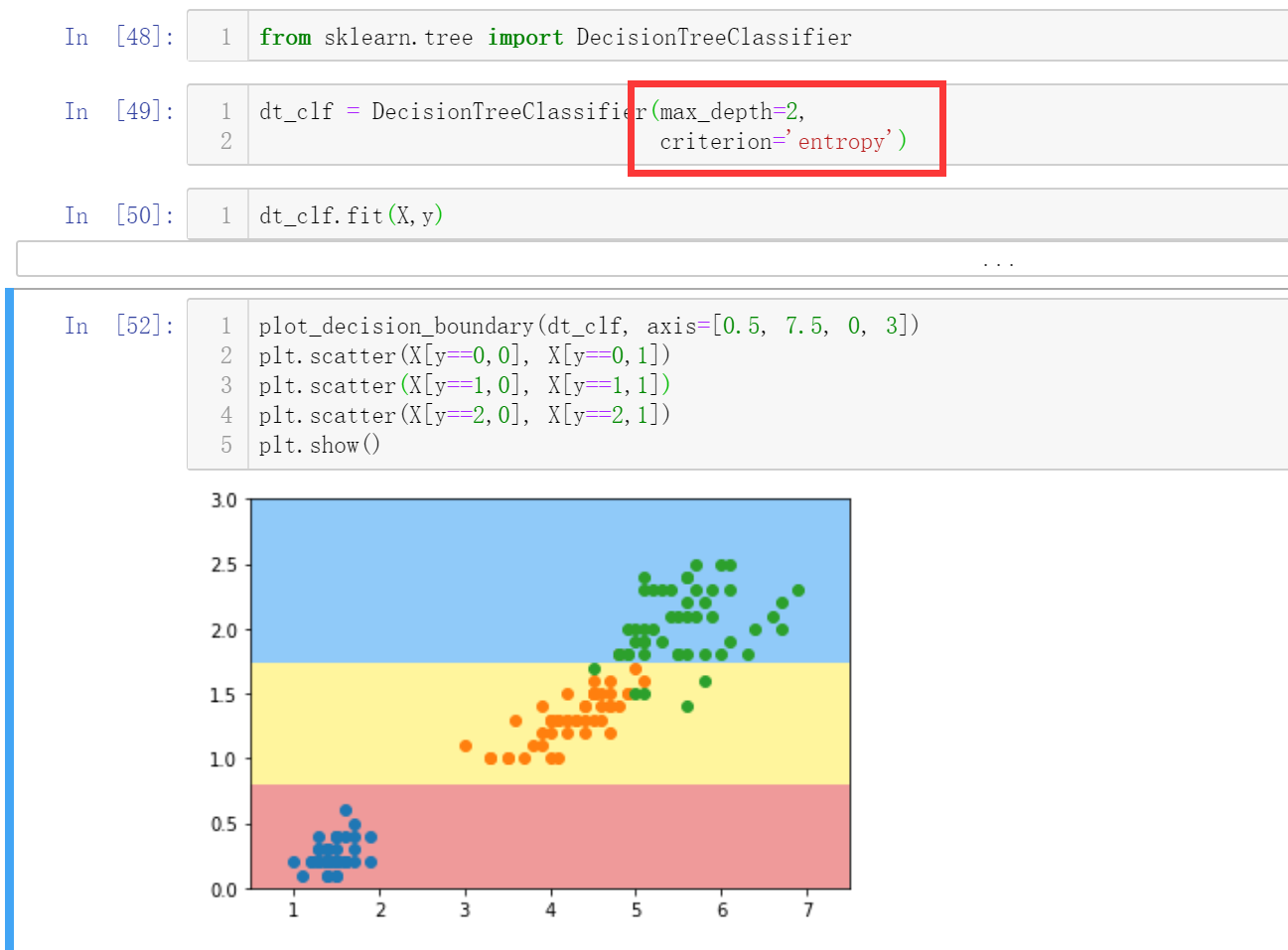
但是我加上random_state之后,出来的结果就视频上一样了,但是我最后求出来的best_entropy都是和视频一样,不管加不加random_state.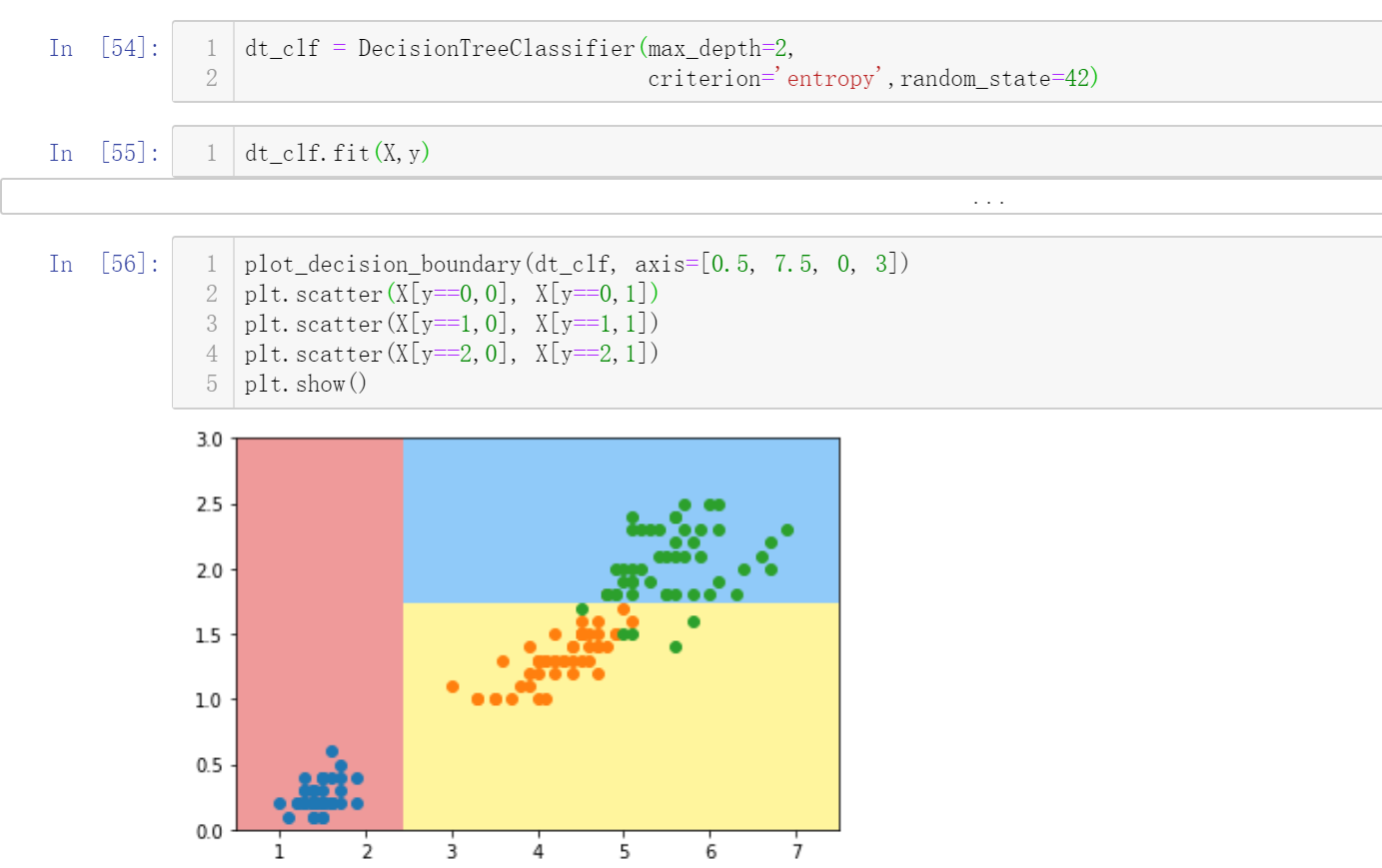
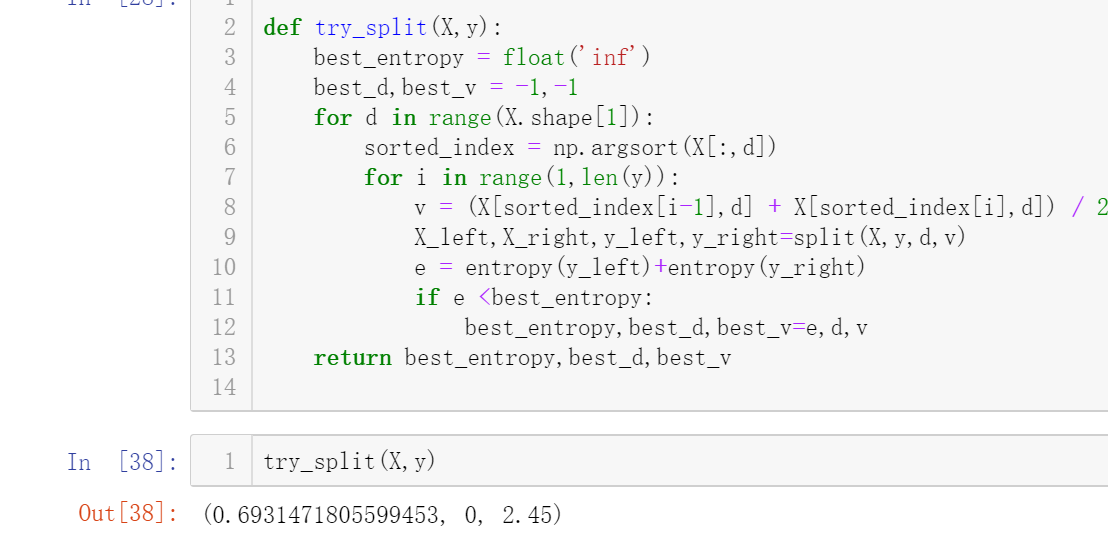
也就是说,我如果没加上random_state,我最后求出来的entropy是错误的。
所以问下老师,这个random_state具体是有什么作用呢?
1309
收起
正在回答 回答被采纳积分+3
1回答

相似问题
子类传入的dict参数起什么作用
1235
0
2


请教老师 这个工作流是做什么的?
1402
0
4




enter_key没起作用,这是怎么回事,也不报错
1044
0
3


filter没起作用?
1209
0
3


set值是可变的,可是我操作了一下,没有变,想问下是什么地方不对
1174
0
4




登录后可查看更多问答,登录/注册








